Ennen kuin käytät pandan kääntötaulukkoa, varmista, että ymmärrät tietosi ja kysymyksesi, jotka yrität ratkaista kääntötaulukon kautta. Tällä menetelmällä voit tuottaa tehokkaita tuloksia. Kerromme tässä artikkelissa, kuinka luoda pivot-taulukko pandas pythonissa.
Lue tiedot Excel-tiedostosta
Olemme ladanneet Excel-tietokannan elintarvikemyynnistä. Ennen toteutuksen aloittamista sinun on asennettava joitain paketteja Excel-tietokantatiedostojen lukemiseen ja kirjoittamiseen. Kirjoita seuraava komento pycharm-editorisi pääteosaan:
pip install xlwt openpyxl xlsxwriter xlrd
Lue nyt tiedot Excel-taulukosta. Tuo vaaditut pandan kirjastot ja muuta tietokannan polkua. Suorittamalla seuraava koodi, tiedot voidaan noutaa tiedostosta.
tuoda pandoja pd: nätuo numerotunnus nimellä np
dtfrm = pd.read_excel ('C: / Users / DELL / Desktop / foodsalesdata.xlsx ')
tulosta (dtfrm)
Täällä tiedot luetaan elintarvikemyynnin Excel-tietokannasta ja siirretään datakehyksen muuttujaan.
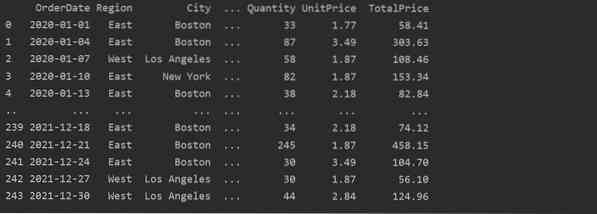
Luo pivot-taulukko Pandas Pythonilla
Alla olemme luoneet yksinkertaisen kääntötaulukon käyttämällä elintarvikemyyntitietokantaa. Pivot-taulukon luomiseen tarvitaan kaksi parametria. Ensimmäinen on data, jonka olemme siirtäneet datakehykseen, ja toinen on hakemisto.
Pivot-tiedot hakemistossa
Hakemisto on pivot-taulukon ominaisuus, jonka avulla voit ryhmitellä tietosi vaatimusten mukaan. Tässä olemme ottaneet indeksiksi 'Tuote' perustason pivot-taulukon luomiseksi.
tuoda pandoja pd: nätuo numerotunnus nimellä np
datakehys = pd.read_excel ('C: / Users / DELL / Desktop / foodsalesdata.xlsx ')
pivot_tble = pd.pivot_table (tietokehys, hakemisto = ["Tuote"])
tulosta (pivot_tble)
Seuraava tulos näkyy yllä olevan lähdekoodin suorittamisen jälkeen:
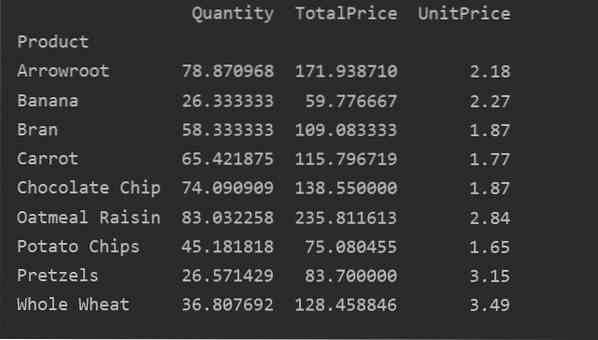
Määritä nimenomaisesti sarakkeet
Jos haluat analysoida tietojasi tarkemmin, määritä sarakkeiden nimet nimen avulla. Esimerkiksi haluamme näyttää tuloksessa kunkin tuotteen ainoan UnitPrice-hinnan. Lisää tätä varten arvoparametri pivot-taulukkoon. Seuraava koodi antaa saman tuloksen:
tuoda pandoja pd: nätuo numerotunnus nimellä np
datakehys = pd.read_excel ('C: / Users / DELL / Desktop / foodsalesdata.xlsx ')
pivot_tble = pd.pivot_table (tietokehys, hakemisto = 'Tuote', arvot = 'Yksikköhinta')
tulosta (pivot_tble)
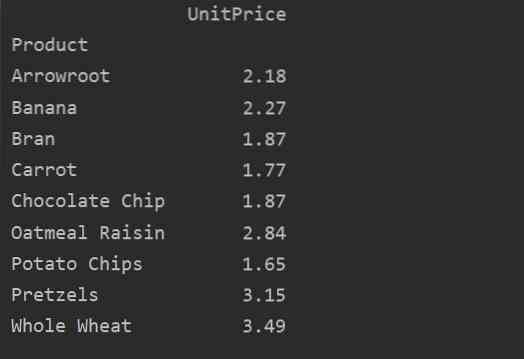
Pivot-data monihakemistolla
Tiedot voidaan ryhmitellä useamman kuin yhden ominaisuuden perusteella indeksinä. Usean indeksin lähestymistapaa käyttämällä voit saada tarkempia tuloksia tietojen analysointia varten. Esimerkiksi tuotteet kuuluvat eri luokkiin. Joten voit näyttää 'Tuote' ja 'Luokka' -hakemiston käytettävissä olevilla 'Määrä' ja 'Yksikköhinta' jokaisella tuotteella seuraavasti:
tuoda pandoja pd: nätuo numerotunnus nimellä np
datakehys = pd.read_excel ('C: / Users / DELL / Desktop / foodsalesdata.xlsx ')
pivot_tble = pd.pivot_table (datakehys, hakemisto = ["Luokka", "Tuote", arvot = ["Yksikköhinta", "Määrä"])
tulosta (pivot_tble)
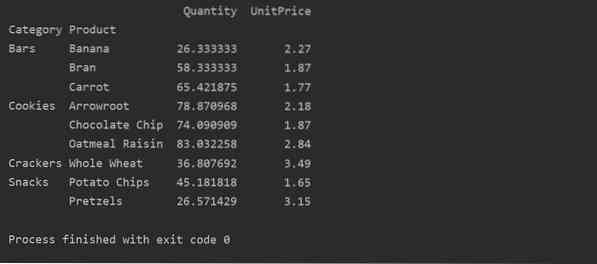
Yhdistämistoiminnon käyttäminen pivot-taulukossa
Pivot-taulukossa aggfuncia voidaan soveltaa eri ominaisuusarvoille. Tuloksena oleva taulukko on yhteenveto ominaisuustiedoista. Koontitoiminto koskee ryhmätietoja pivot_table-taulukossa. Oletusarvoisesti aggregaattitoiminto on np.tarkoittaa(). Mutta käyttäjien vaatimusten perusteella eri dataominaisuuksiin voidaan soveltaa erilaisia koontitoimintoja.
Esimerkki:
Olemme soveltaneet aggregaattitoimintoja tässä esimerkissä. Np.sum () -funktiota käytetään 'Määrä' -ominaisuuteen ja np.mean () -toiminto UnitPrice-ominaisuudelle.
tuoda pandoja pd: nätuo numerotunnus nimellä np
datakehys = pd.read_excel ('C: / Users / DELL / Desktop / foodsalesdata.xlsx ')
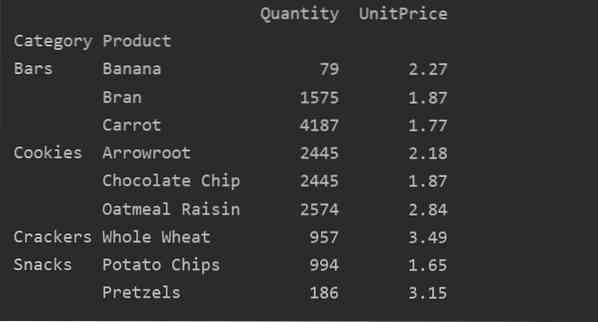
pivot_tble = pd.pivot_table (tietokehys, hakemisto = ["Luokka", "Tuote"), aggfunc = 'Määrä': np.summa, 'UnitPrice': np.tarkoittaa)
tulosta (pivot_tble)
Kun yhdistämistoiminto on sovellettu eri ominaisuuksiin, saat seuraavan tuloksen:
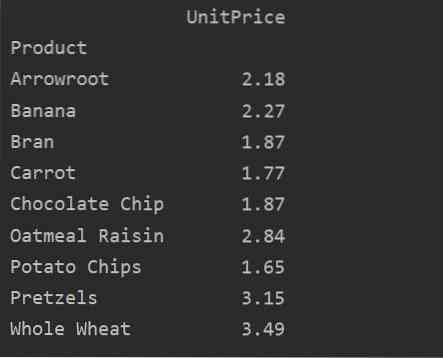
Arvo-parametrin avulla voit myös käyttää aggregaattitoimintoa tietylle ominaisuudelle. Jos et määritä ominaisuuden arvoa, se yhdistää tietokannan numeeriset ominaisuudet. Noudattamalla annettua lähdekoodia voit käyttää aggregaattitoimintoa tietylle ominaisuudelle:
tuoda pandoja pd: nätuo numerotunnus nimellä np
datakehys = pd.read_excel ('C: / Users / DELL / Desktop / foodsalesdata.xlsx ')
pivot_tble = pd.pivot_table (tietokehys, hakemisto = ['Tuote]], arvot = [' Yksikköhinta '], aggfunc = np.tarkoittaa)
tulosta (pivot_tble)
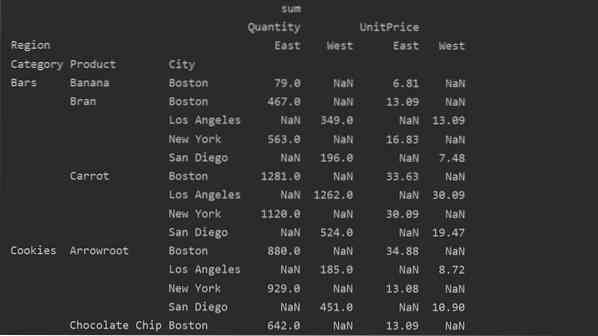
Eri arvot vs. Sarakkeet pivot-taulukossa
Arvot ja sarakkeet ovat tärkein sekava kohta pivot_table-taulukossa. On tärkeää huomata, että sarakkeet ovat valinnaisia kenttiä, jotka näyttävät tuloksena olevan taulukon arvot vaakatasossa ylhäällä. Yhdistämistoiminto aggfunc koskee listattuja arvokenttiä.
tuoda pandoja pd: nätuo numerotunnus nimellä np
datakehys = pd.read_excel ('C: / Users / DELL / Desktop / foodsalesdata.xlsx ')
pivot_tble = pd.pivot_table (tietokehys, hakemisto = ['Luokka', 'Tuote', 'Kaupunki'], arvot = ['Yksikköhinta', 'Määrä'],
sarakkeet = ['alue'], aggfunc = [np.summa])
tulosta (pivot_tble)
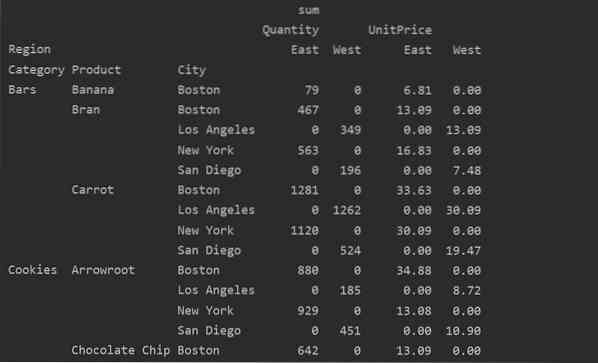
Puuttuvien tietojen käsittely pivot-taulukossa
Voit myös käsitellä puuttuvat arvot Pivot-taulukossa käyttämällä 'fill_value' Parametri. Tämän avulla voit korvata NaN-arvot uudella arvolla, jonka annat täyttämistä varten.
Esimerkiksi poistimme kaikki nolla-arvot yllä olevasta tulostaulukosta suorittamalla seuraavan koodin ja korvaamalla NaN-arvot 0: lla koko tuloksena olevassa taulukossa.
tuoda pandoja pd: nätuo numerotunnus nimellä np
datakehys = pd.read_excel ('C: / Users / DELL / Desktop / foodsalesdata.xlsx ')
pivot_tble = pd.pivot_table (tietokehys, hakemisto = ['Luokka', 'Tuote', 'Kaupunki'], arvot = ['Yksikköhinta', 'Määrä'],
sarakkeet = ['alue'], aggfunc = [np.summa], täyttöarvo = 0)
tulosta (pivot_tble)
Suodatus pivot-taulukossa
Kun tulos on luotu, voit käyttää suodatinta vakiotietokehystoiminnolla. Otetaan esimerkki. Suodata tuotteet, joiden UnitPrice on alle 60. Se näyttää tuotteet, joiden hinta on alle 60.
tuoda pandoja pd: nätuo numerotunnus nimellä np
datakehys = pd.read_excel ('C: / Users / DELL / Desktop / foodsalesdata.xlsx ', index_col = 0)
pivot_tble = pd.pivot_table (tietokehys, hakemisto = 'Tuote', arvot = 'Yksikköhinta', aggfunc = 'Summa')
low_price = pivot_tble [pivot_tble ['UnitPrice'] < 60]
tulosta (alhainen hinta)

Käyttämällä toista kyselymenetelmää voit suodattaa tuloksia. Esimerkiksi, olemme suodattaneet evästeiden luokan seuraavien ominaisuuksien perusteella:
tuoda pandoja pd: nätuo numerotunnus nimellä np
datakehys = pd.read_excel ('C: / Users / DELL / Desktop / foodsalesdata.xlsx ', hakemisto_kol = 0)
pivot_tble = pd.pivot_table (tietokehys, hakemisto = ["Luokka", "Kaupunki", "Alue"], arvot = ["Yksikköhinta", "Määrä"], aggfunc = np.summa)
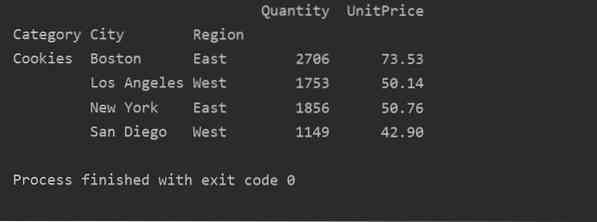
pt = kääntyvä_taulukko.kysely ('Luokka == ["Evästeet"]' ')
tulosta (pt)
Tuotos:
Visualisoi pivot-taulukon tiedot
Voit visualisoida pivot-taulukon tiedot seuraavasti:
tuoda pandoja pd: nätuo numerotunnus nimellä np
tuoda matplotlib.pyplot kuten plt
datakehys = pd.read_excel ('C: / Users / DELL / Desktop / foodsalesdata.xlsx ', hakemisto_kol = 0)
pivot_tble = pd.pivot_table (tietokehys, hakemisto = ["Luokka", "Tuote"], arvot = ["Yksikköhinta"])
pivot_tble.juoni (kind = 'bar');
plt.näytä()
Yllä olevassa visualisoinnissa olemme osoittaneet eri tuotteiden yksikköhinnan ja kategoriat.

Johtopäätös
Tutkimme, kuinka voit luoda pivot-taulukon datakehyksestä Pandas pythonin avulla. Pivot-taulukon avulla voit luoda syvällisiä oivalluksia tietojoukoihisi. Olemme nähneet, kuinka yksinkertainen pivot-taulukko luodaan monihakemistolla ja käytetään suodattimia pivot-taulukoihin. Lisäksi olemme osoittaneet piirtämään taulukkotiedot ja täyttämään puuttuvat tiedot.


