Tesseract OCR: n asentaminen Linuxiin
Tesseract OCR on oletusarvoisesti käytettävissä useimmissa Linux-jakeluissa. Voit asentaa sen Ubuntun alla olevan komennon avulla:
$ sudo apt install tesseract-ocrYksityiskohtaiset ohjeet muista jakeluista ovat saatavilla tässä. Vaikka Tesseract OCR on oletusarvoisesti saatavana useiden Linux-jakelujen arkistoissa, on suositeltavaa asentaa uusin versio yllä mainitusta linkistä tarkkuuden ja jäsentämisen parantamiseksi.
Lisäkielien tuen asentaminen Tesseract OCR: ssä
Tesseract OCR sisältää tuen yli 100 kielen tekstin tunnistamiseen. Saat kuitenkin tukea vain englanninkielisen tekstin havaitsemiseen oletusasennuksella Ubuntussa. Lisää tuki muiden kielten jäsentämiseen Ubuntussa suorittamalla komento seuraavassa muodossa:
$ sudo apt asenna tesseract-ocr-hinYllä oleva komento lisää tuen hindinkielelle Tesseract OCR: ään. Joskus saat parempaa tarkkuutta ja tuloksia asentamalla kieliskriptien tuen. Esimerkiksi tesseract-paketin asentaminen ja käyttö Devanagari-komentosarjalle "tesseract-ocr-script-deva" antoi minulle paljon tarkempia tuloksia kuin "tesseract-ocr-hin" -paketin käyttö.
Ubuntusta löydät oikeat pakettien nimet kaikille kielille ja komentosarjoille suorittamalla alla olevan komennon:
$ apt-välimuisti etsi tesseract-Kun olet löytänyt oikean asennettavan paketin nimen, korvaa merkkijono “tesseract-ocr-hin” sillä ensimmäisessä yllä määritetyssä komennossa.
Tekstin poimiminen kuvista Tesseract OCR: n avulla
Otetaan esimerkki alla olevasta kuvasta (otettu Wikipedia-sivulta Linuxille):

Jos haluat purkaa tekstiä yllä olevasta kuvasta, sinun on suoritettava komento seuraavassa muodossa:
$ tesseract -sieppaus.png-lähtö -l engYllä olevan komennon suorittaminen antaa seuraavan tuloksen:
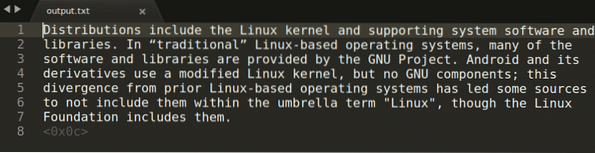
Yllä olevassa komennossa "kaapata.png ”viittaa kuvaan, josta haluat purkaa tekstin. Siepattu lähtö tallennetaan sitten “lähtöön.txt ”-tiedosto. Voit vaihtaa kieltä korvaamalla “eng” -argumentin omalla valinnallasi. Jos haluat nähdä kaikki kelvolliset kielet, suorita alla oleva komento:
$ tesseract --list-langsSe näyttää lyhennyskoodit kaikille kielille, joita Tesseract OCR tukee järjestelmässäsi. Oletusarvoisesti se näyttää vain "eng" tuotoksena. Jos kuitenkin asennat paketteja muille kielille, kuten yllä on selitetty, tämä komento luetteloi lisää kieliä, joiden avulla voit tunnistaa tekstin (ISO 639 3-kirjaimiset kielikoodit).
Jos kuvassa on tekstiä useilla kielillä, määritä ensin ensisijainen kieli ja sen jälkeen lisäkielet plusmerkeillä erotettuna.
$ tesseract -sieppaus.png-lähtö -l eng + fraJos haluat tallentaa lähdön haettavana PDF-tiedostona, suorita komento seuraavassa muodossa:
$ tesseract -sieppaus.png output -l fin pdfHuomaa, että haettava PDF-tiedosto ei sisällä muokattavaa tekstiä. Se sisältää alkuperäisen kuvan, jossa on lisäkerros, joka sisältää tunnistetun tekstin kuvan päällä. Joten vaikka pystyt etsimään tarkasti tekstiä PDF-tiedostosta millä tahansa PDF-lukijalla, et voi muokata tekstiä.
Toinen huomioitava asia on, että tekstintunnistuksen tarkkuus kasvaa huomattavasti, jos kuvatiedosto on korkealaatuista. Käytä valinnan mukaan aina häviöttömiä tiedostomuotoja tai PNG-tiedostoja. JPG-tiedostojen käyttäminen ei välttämättä tuota parhaita tuloksia.
Pura teksti monisivuisesta PDF-tiedostosta
Tesseract OCR ei luonnollisesti tue tekstin purkamista PDF-tiedostoista. On kuitenkin mahdollista poimia tekstiä monisivuisesta PDF-tiedostosta muuntamalla jokainen sivu kuvatiedostoksi. Suorita alla oleva komento, jos haluat muuntaa PDF-tiedoston kuvasarjaksi:
$ pdftoppm -png-tiedosto.pdf-tiedostoKutakin PDF-tiedoston sivua varten saat vastaavan “output-1.png ”,“ lähtö-2.png ”-tiedosto ja niin edelleen.
Nyt, kun haluat purkaa tekstiä näistä kuvista yhdellä komennolla, joudut käyttämään “for loop” -komentoa:
$ for i sisään *.png; tee tesseract "$ i" "output- $ i" -l eng; tehty;Yllä olevan komennon suorittaminen poimii tekstiä kaikista.png ”-tiedostot, jotka löytyvät työhakemistosta ja tallentavat tunnistetun tekstin kansioon” output-original_filename.txt ”-tiedostot. Voit muokata komennon keskiosaa tarpeidesi mukaan.
Jos haluat yhdistää kaikki tunnistettua tekstiä sisältävät tekstitiedostot, suorita alla oleva komento:
$ kissa *.txt> liittyi.txtProsessi tekstin purkamiseksi monisivuisesta PDF-tiedostosta haettaviin PDF-tiedostoihin on lähes sama. Komennolle on annettava ylimääräinen "pdf" -argumentti:
$ for i sisään *.png; tee tesseract "$ i" "output- $ i" -l fin pdf; tehty;Jos haluat yhdistää kaikki tunnistettavat tekstit sisältävät haettavat PDF-tiedostot, suorita alla oleva komento:
$ pdfunite *.pdf liittyi.pdfSekä “pdftoppm” että „pdfunite” asennetaan oletuksena Ubuntun uusimpaan vakaaseen versioon.
Tekstin purkamisen edut ja haitat TXT-tiedostoissa ja haettavissa PDF-tiedostoissa
Jos purat tunnistetun tekstin TXT-tiedostoihin, saat muokattavan tekstin. Asiakirjan muotoilu menetetään kuitenkin (lihavoitu, kursivoitu merkki jne.). Haettavat PDF-tiedostot säilyttävät alkuperäisen muotoilun, mutta menetät tekstin muokkausominaisuudet (voit silti kopioida raakaa tekstiä). Jos avaat haettavan PDF-tiedoston missä tahansa PDF-editorissa, tiedostoon upotetaan kuvat (t) eikä raakaa tekstiä. Haettavien PDF-tiedostojen muuntaminen HTML- tai EPUB-tiedostoiksi antaa myös upotetut kuvat.
Johtopäätös
Tesseract OCR on yksi nykyisin eniten käytettyjä OCR-moottoreita. Se on ilmainen, avoimen lähdekoodin ja tukee yli sataa kieltä. Kun käytät Tesseract OCR -tekniikkaa, muista käyttää korkean resoluution kuvia ja korjata kielikoodit komentoriviargumenteissa tekstin tunnistuksen tarkkuuden parantamiseksi.


