In this lesson on Machine Learning with scikit-learn, we will learn various aspects of this excellent Python package which allows us to apply simple and complex Machine Learning capabilities on a diverse set of data along with functionalities to test the hypothesis we establish.
The scikit-learn package contains simple and efficient tools to apply data mining and data analysis on datasets and these algorithms are available to be applied in different contexts. It is an open-source package available under a BSD license, which means that we can use this library even commercially. It is built on top of matplotlib, NumPy and SciPy so it is versatile in nature. We will make use of Anaconda with Jupyter notebook to present examples in this lesson.
What scikit-learn provides?
The scikit-learn library focuses completely on data modelling. Please note that there are no major functionalities present in the scikit-learn when it comes to loading, manipulating and summarizing data. Here are some of the popular models which scikit-learn provides to us:
- Clustering to group labelled data
- Datasets to provide test data sets and investigate model behaviours
- Cross Validation to estimate the performance of supervised models on unseen data
- Ensemble methods to combining the predictions of multiple supervised models
- Feature extraction to defining attributes in image and text data
Install Python scikit-learn
Just a note before starting the installation process, we use a virtual environment for this lesson which we made with the following command:
python -m virtualenv scikitsource scikit/bin/activate
Once the virtual environment is active, we can install pandas library within the virtual env so that examples we create next can be executed:
pip install scikit-learnOr, we can use Conda to install this package with the following command:
conda install scikit-learnWe see something like this when we execute the above command:

Once the installation completes with Conda, we will be able to use the package in our Python scripts as:
import sklearnLet's start using scikit-learn in our scripts to develop awesome Machine Learning algorithms.
Importing Datasets
One of the cool thing with scikit-learn is that it comes pre-loaded with sample datasets with which it is easy to get started quickly. The datasets are the iris and digits datasets for classification and the boston house prices dataset for regression techniques. In this section, we will look at how to load and start using the iris dataset.
To import a dataset, we first have to import the correct module followed by getting the hold to the dataset:
from sklearn import datasetsiris = datasets.load_iris()
digits = datasets.load_digits()
digits.data
Once we run the above code snippet, we will see the following output:

All of the output is removed for brevity. This is the dataset we will be majorly using in this lesson but most of the concepts can be applied to generally all of the datasets.
Just a fun fact to know that there are multiple modules present in the scikit ecosystem, one of which is learn used for Machine Learning algorithms. See this page for many other modules present.
Exploring the Dataset
Now that we have imported the provided digits dataset into our script, we should start gathering basic information about the dataset and that is what we will do here. Here is the basic things you should explore while looking to find information about a dataset:
- The target values or labels
- The description attribute
- The keys available in the given dataset
Let us write a short code snippet to extract the above three information from our dataset:
print('Target: ', digits.target)print('Keys: ', digits.keys())
print('Description: ', digits.DESCR)
Once we run the above code snippet, we will see the following output:
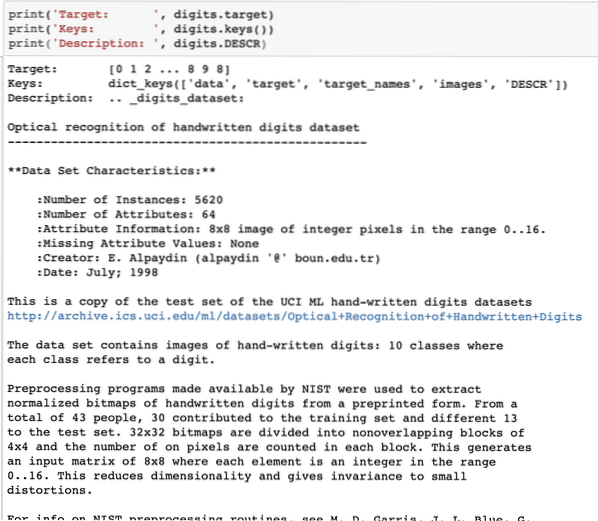
Please note that the variable digits is not straightforward. When we printed out the digits dataset, it actually contained numpy arrays. We will see how we can access these arrays. For this, take note of the keys available in the digits instance we printed in the last code snippet.
We will start by getting the shape of the array data, which is the rows and columns that array has. For this, first we need to get the actual data and then get its shape:
digits_set = digits.dataprint(digits_set.shape)
Once we run the above code snippet, we will see the following output:

This means that we have 1797 samples present in our dataset along with 64 data features (or columns). Also, we also have some target labels which we will visualise here with the help of matplotlib. Here is a code snippet which help us to do so:
import matplotlib.pyplot as plt# Merge the images and target labels as a list
images_and_labels = list(zip(digits.images, digits.target))
for index, (image, label) in enumerate(images_and_labels[:8]):
# initialize a subplot of 2X4 at the i+1-th position
plt.subplot(2, 4, index + 1)
# No need to plot any axes
plt.axis('off')
# Show images in all subplots
plt.imshow(image, cmap=plt.cm.gray_r,interpolation='nearest')
# Add a title to each subplot
plt.title('Training: ' + str(label))
plt.show()
Once we run the above code snippet, we will see the following output:

Note how we zipped the two NumPy arrays together before plotting them onto a 4 by 2 grid without any axes information. Now, we are sure about the information we have about the dataset we are working with.
Now that we know that we have 64 data features (which are a lot of features by the way), it is challenging to visualise the actual data. We have a solution for this though.
Principal Component Analysis (PCA)
This is not a tutorial about PCA, but let us give a small idea about what it is. As we know that to reduce the number of features from a dataset, we have two techniques:
- Feature Elimination
- Feature Extraction
While the first technique faces the issue of lost data features even when they might have been important, the second technique doesn't suffer from the issue as with the help of PCA, we construct new data features (less in number) where we combine the input variables in such a way, that we can leave out the “least important” variables while still retaining the most valuable parts of all of the variables.
As anticipated, PCA helps us to reduce the high-dimensionality of data which is a direct result of describing an object using many data features. Not only digits but many other practical datasets have high number of features which includes financial institutional data, weather and economy data for a region etc. When we perform PCA on the digits dataset, our aim will be to find just 2 features such that they have most of the characteristics of the dataset.
Let's write a simple code snippet to apply PCA on the digits dataset to get our linear model of just 2 features:
from sklearn.decomposition import PCAfeature_pca = PCA(n_components=2)
reduced_data_random = feature_pca.fit_transform(digits.data)
model_pca = PCA(n_components=2)
reduced_data_pca = model_pca.fit_transform(digits.data)
reduced_data_pca.shape
print(reduced_data_random)
print(reduced_data_pca)
Once we run the above code snippet, we will see the following output:
[[ -1.2594655 21.27488324][ 7.95762224 -20.76873116]
[ 6.99192123 -9.95598191]
…
[ 10.8012644 -6.96019661]
[ -4.87210598 12.42397516]
[ -0.34441647 6.36562581]]
[[ -1.25946526 21.27487934]
[ 7.95761543 -20.76870705]
[ 6.99191947 -9.9559785 ]
…
[ 10.80128422 -6.96025542]
[ -4.87210144 12.42396098]
[ -0.3443928 6.36555416]]
In the above code, we mention that we only need 2 features for the dataset.
Now that we have good knowledge about our dataset, we can decide what kind of machine learning algorithms we can apply on it. Knowling a dataset is important because that is how we can decide about what information can be extracted out of it and with which algorithms. It also helps us to test the hypothesis we establish while predicting future values.
Applying k-means clustering
The k-means clustering algorithm is one of the easiest clustering algorithm for unsupervised learning. In this clustering, we have some random number of clusters and we classify our data points in one these clusters. The k-means algorithm will find the nearest cluster for each of the given data point and assign that data point to that cluster.
Once the clustering is done, the centre of the cluster is recomputed, the data points are assigned new clusters if there any changes. This process is repeated until the data points stop changing there clusters to achieve stability.
Let's simply apply this algorithm without any preprocessing of the data. For this strategy, the code snippet will be quite easy:
from sklearn import clusterk = 3
k_means = cluster.KMeans(k)
# fit data
k_means.fit(digits.data)
# print results
print(k_means.labels_[::10])
print(digits.target[::10])
Once we run the above code snippet, we will see the following output:
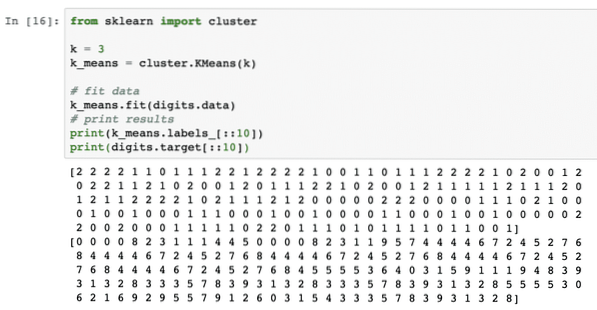
In above output, we can see different clusters being provided to each of the data point.
Conclusion
In this lesson, we looked at an excellent Machine Learning library, scikit-learn. We learned that there are many other modules available in the scikit family and we applied simple k-means algorithm on provided dataset. There are many more algorithms which can be applied on the dataset apart from k-means clustering which we applied in this lesson, we encourage you to do so and share your results.
Please share your feedback on the lesson on Twitter with @sbmaggarwal and @LinuxHint.


