Grepiä on käytetty laajalti Linux-järjestelmissä, kun hän on työskennellyt joidenkin tiedostojen parissa, etsinyt tiettyä mallia ja monia muita. Tällä kertaa käytämme grep-komentoa näyttääksesi rivit ennen ja jälkeen tietyssä tiedostossa käytetyn vastaavan avainsanan. Tätä tarkoitusta varten käytämme "-A", "-B" ja "-C" lippua koko opetusoppaassamme. Joten sinun on suoritettava jokainen vaihe ymmärtämisen parantamiseksi. Varmista, että sinulla on Ubuntu 20.04 Linux-järjestelmä asennettuna.
Ensinnäkin sinun on avattava Linux-komentorivipäätte, jotta voit aloittaa grep-työskentelyn. Olet tällä hetkellä Ubuntu-järjestelmän kotihakemistossa heti komentorivipäätteen avaamisen jälkeen. Joten yritä luetella kaikki tiedostot ja kansiot Linux-järjestelmän kotihakemistossa alla olevan ls-komennon avulla, niin saat kaikki. Voit nähdä, että siinä on joitain tekstitiedostoja ja joitain kansioita.
Ls
Esimerkki 01: '-A' ja '-B' käyttäminen
Edellä esitetyistä tekstitiedostoista katsomme joitain näistä ja yritämme soveltaa niihin grep-komentoa. Avataan tekstitiedosto ”yksi.txt ”käyttäen ensin suosittua kissa-komentoa alla:
$ kissa yksi.txt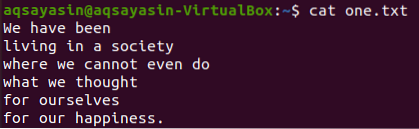
Näemme ensin joitain tiettyjä sanoja vastaavia tässä tekstitiedostossa alla olevan grep-komennon avulla. Etsimme sanaa "me" tekstitiedostosta "yksi.txt ”käyttäen grep-käskyä. Lähdössä näkyy kaksi riviä tekstitiedostosta, joissa on "me".
$ grep me yksi.txt
Joten tässä esimerkissä näytämme rivit ennen ja jälkeen tietyn sanavastaavuuden joissakin tekstitiedostoissa. Joten käyttämällä samaa tekstitiedostoa "yksi.txt "olemme sovittaneet sanan" me "samalla, kun näytämme edeltävät kolme riviä alla. Lippu "-B" tarkoittaa "Ennen". Tuloksessa näkyy vain 2 riviä ennen tiettyä sanariviä, koska tiedostossa ei ole enempää rivejä tietyn sanan edessä. Se osoittaa myös nämä rivit, joissa kyseinen sana on läsnä.
$ grep -B 3 me yksi.txt
Käytetään samaa avainsanaa "me" tästä tiedostosta näyttämään rivin jälkeiset 3 riviä, joissa on sana "me". Lippu "-A" esittää "After". Lähdössä näkyy jälleen vain 2 riviä, koska siinä ei ole enemmän rivejä tiedostossa.
$ grep -A 3 me yksi.txt
Joten, käytämme uutta avainsanaa vastaavuuksien löytämiseksi ja näytämme rivit tai rivit ennen ja jälkeen rivin, jossa se sijaitsee. Joten olemme käyttäneet sanaa "voi" sovitettavaksi. Rivinumero on tässä tapauksessa sama. 3 riviä vastaavan sanan "voi" jälkeen on näytetty alla grep-komennolla.
$ grep -A 3 voi yksi.txt
Näet, että tulos näkyy vastaavan sanan rivejä käyttäen avainsanalla "voi". Sen sijaan se näyttää vain kaksi riviä ennen vastaavan sanan riviä, koska sen edessä ei ole enää rivejä.
$ grep -B 3 voi yhden.txt
Esimerkki 02: '-A': n ja '-B: n käyttö
Otetaan toinen tekstitiedosto ”kaksi.txt, ”kotihakemistosta ja näytä sen sisältö alla olevan” cat ”-komennon avulla.
$ kissa kaksi.txt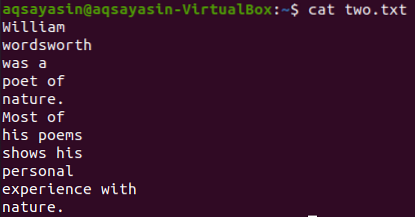
Näytetään 5 riviä ennen sanaa "Most" tiedostosta "two.txt ”käyttämällä grep-komentoa. Tuloksessa näkyy 5 riviä ennen kuin rivi sisältää tietyn sanan.
$ grep -B 5 Eniten kaksi.txt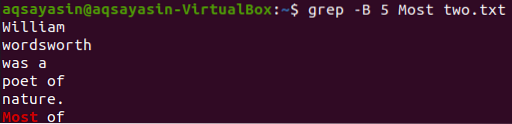
Grep-komento näyttää viisi riviä sanan "Most" jälkeen tekstitiedostosta "two.txt ”on annettu alla.
$ grep -A 5 Eniten kaksi.txt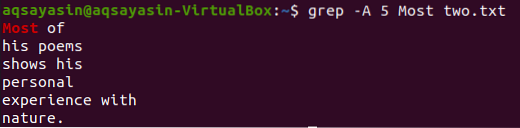
Vaihdetaan haettava avainsana. Käytämme sanaa "of" avainsanana, joka tällä kertaa sovitetaan yhteen. Näytä 2 riviä ennen sanaa "of" tekstitiedostosta "two.txt ”voidaan tehdä alla olevan grep-komennon avulla. Tuloksessa näkyy kaksi riviä avainsanalle ”of”, koska se tulee tiedostoon kahdesti. Siten lähtö sisältää yli 2 riviä.
$ grep -B 2 kahdesta.txt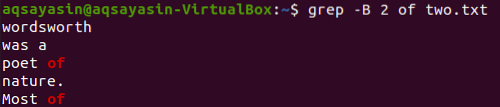
Nyt näytetään 2 tiedostoriviä “kaksi.txt ”rivin jälkeen, joka sisältää avainsanan” of ”, voidaan tehdä alla olevan komennon avulla. Lähdössä näkyy jälleen yli 2 riviä.
$ grep -A 2 kahdesta.txt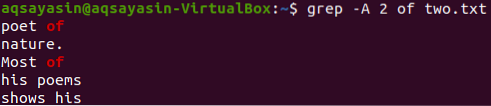
Esimerkki 03: '-C': n käyttö
Toista lippua, -C, on käytetty vastaavien sanojen edessä ja jälkeen olevien rivien näyttämiseen. Näytetään tiedoston sisältö ”yksi.txt ”käyttämällä kissa-komentoa.
$ kissa yksi.txt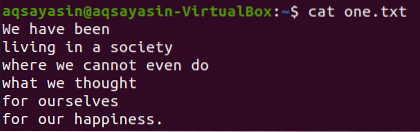
Valitsemme "yhteiskunta" vastaavaksi avainsanaksi. Alla oleva grep-komento näyttää 2 riviä ennen ja 2 riviä sen rivin jälkeen, joka sisältää sanan "yhteiskunta". Lähdössä näkyy yksi rivi ennen tiettyä sanariviä ja 2 riviä sen jälkeen.
$ grep -C 2 yhteiskunnan yksi.txt
Katsotaanpa tiedoston "kaksi.txt ”käyttämällä alla olevaa kissa-komentoa.
$ kissa kaksi.txt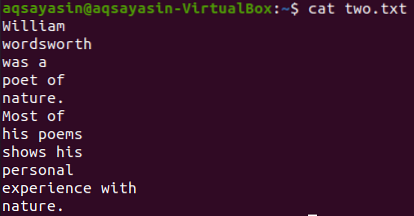
Tässä kuvassa käytämme "runoja" avainsanana. Joten suorita alla oleva komento tätä varten. Lähdössä näkyy kaksi riviä ennen ja kaksi riviä vastaavan sanan jälkeen.
$ grep -C 2 runoja kaksi.txt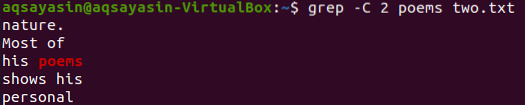
Käytetään vielä yhtä avainsanaa tiedostosta “two.txt ”vastaava. Kulutamme tällä kertaa avainsanana "luonto". Kokeile siis alla olevaa komentoa käyttäessäsi ”-C” lippuna, jolla on avainsana ”nature” tiedostosta ”two”.txt ”. Tällä kertaa lähdössä on enemmän kuin kaksi riviä. Koska tiedosto sisältää sanan "luonto" useammin kuin kerran, se on syy siihen. Ensin avainsanalla "luonto" on kaksi riviä ennen ja kaksi riviä sen jälkeen. Vaikka toinen vastasi samaa avainsanaa, "luonnolla" on kaksi riviä edessään, mutta sen jälkeen ei ole rivejä, koska se on tiedoston viimeisellä rivillä.
$ grep -C 2 runoja kaksi.txt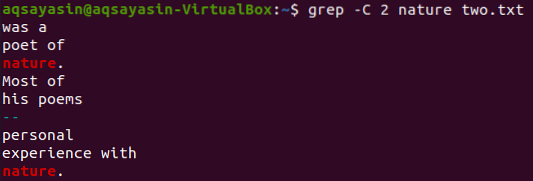
Johtopäätös
Olemme onnistuneet näyttämään rivit ennen tiettyä sanaa ja sen jälkeen grep-käskyä käytettäessä.


