Apache Kafka
For a high-level definition, let us present a short definition for Apache Kafka:
Apache Kafka is a distributed, fault-tolerant, horizontally-scalable, commit log.
Those were some high-level words about Apache Kafka. Let us understand the concepts in detail here.
- Distributed: Kafka divides the data it contains into multiple servers and each of these servers is capable of handling requests from clients for the share of data it contains
- Fault-tolerant: Kafka doesn't have a Single point of Failure. In a SPoF system, like a MySQL database, if the server hosting the database goes down, the application is screwed. In a system which doesnt have a SPoF and consists of multiuple nodes, even if most part of the system goes down, it is still the same for an end user.
- Horizontally-scalable: This kind of scailing refers to adding more machines to existing cluster. This means that Apache Kafka is capable of accepting more nodes in its cluster and providing no down-time for required upgrades to the system. Look at the image below to understand the type of scailing concepts:
- Commit Log: A commit log is a Data Structure just like a Linked List. It appends whatever messages come to it and always maintains their order. Data cannot be deleted from this log until a specified time is reached for that data.
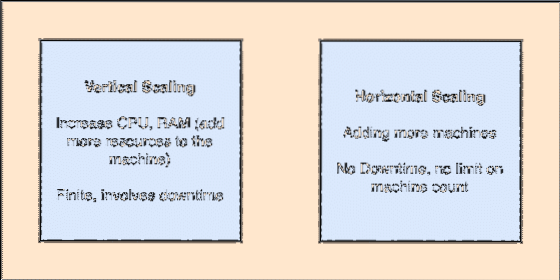
Vertical and Horizontal Scailing
A topic in Apache Kafka is just like a queue where messages are stored. These messages are stored for a configurable amount of time and message is not deleted until this time is achieved, even if it has been consumed by all known consumers.
Kafka is scalable as it is the consumers who actually stores that what message was fetched by them last as an 'offset' value. Let's look at a figure to understand this better: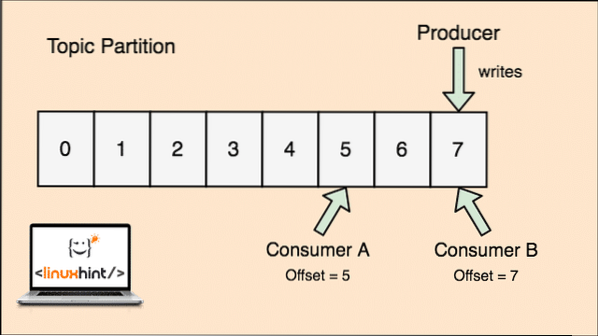
Topic partion and Consumer offset in Apache Kafka
Getting Started with Apache Kafka
To start using Apache Kafka, it must be installed on the machine. To do this, read Install Apache Kafka on Ubuntu.
Make sure you have an active Kafka installation if you want to try examples we present later in the lesson.
How does it work?
With Kafka, the Producer applications publish messages which arrives at a Kafka Node and not directly to a Consumer. From this Kafka Node, messages are consumed by the Consumer applications.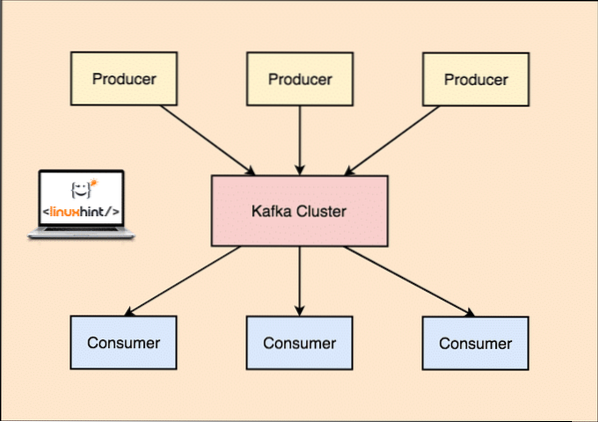
Kafka Producer and Consumer
As a single topic can get a lot of data at one go, to keep Kafka horizontally scalable, each topic is divided into partitions and each partition can live on any node machine of a cluster. Let us try to present it:
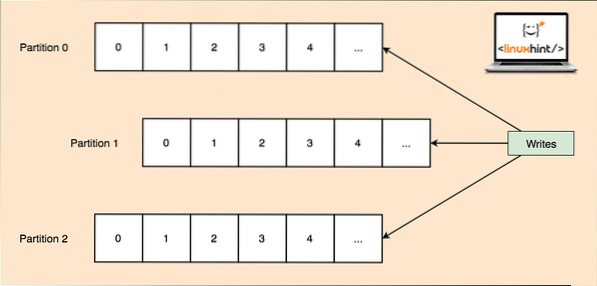
Topic Partitions
Again, Kafka Broker doesn't keep record of which consumer has consumed how many packets of data. It is the consumers responsibility to keep track of data it has consumed.
Persistence to Disk
Kafka persists the message records it gets from Producers on disk and doesn't keep them in the memory. A question which might arise is how this makes things feasible and fast? There were several reasons behind this which makes it an optimal way of managing the message records:
- Kafka follows a protocol of grouping the message records. Producers produces messages which are persisted to disk in large chunks and consumers consumes these message records in large linear chunks as well.
- The reason that the disk writes are linear, is that this makes reads fast due to highly decreased linear disk read time.
- Linear disk operations are optimized by Operating Systems as well by using techniques of write-behind and read-ahead.
- Modern OS also use the concept of Pagecaching which means that they cache some disk data in Free available RAM.
- As Kafka persists data in a uniform standard data in the whole flow from producer till consumer, it makes use of the zero-copy optimization process.
Data Distribution & Replication
As we studied above that a topic is divided into partitions, each message record is replicated on multiple nodes of the cluster to maintain the order and data of each record in case one of the node dies.
Even though a partition is replicated on multiple nodes, there still is a partition leader node through which applications read and write data on the topic and the leader replicates data on other nodes, which are termed as followers of that partition.
If the message record data is highly important to an application, the guarantee of the message record to be safe in one of the nodes can be increased by increasing the replication factor of the Cluster.
What is Zookeeper?
Zookeeper is a highly fault-tolerant, distributed key-value store. Apache Kafka heavily depends on Zookeeper to store cluster mechanics like the heartbeat, distributing updates/configurations, etc).
It allows the Kafka brokers to subscribe to itself and know whenever any change regarding a partition leader and node distribution has happened.
Producer and Consumers applications directly communicate with Zookeeper application to know which node is the partition leader for a topic so that they can perform reads and writes from the partition leader.
Streaming
A Stream Processor is a main component in a Kafka cluster which takes a continual stream of message record data from input topics, process this data and creates a stream of data to output topics which can be anything, from trash to a Database.
It is completely possible to perform simple processing directly using the producer/consumer APIs, though for complex processing like combining streams, Kafka provides an integrated Streams API library but please note that this API is meant to be used within our own codebase and it doesn't run on a broker. It works similar to the consumer API and helps us scale out the stream processing work over multiple applications.
When to use Apache Kafka?
As we studied in above sections, Apache Kafka can be used to deal with a large number of message records which can belong to a virtually infinite number of topics in our systems.
Apache Kafka is an ideal candidate when it comes to using a service which can allow us to follow event-driven architecture in our applications. This is due to its capabilities of data persistence, fault-tolerant and highly distributed architecture where critical applications can rely on its performance.
The scalable and distributed architecture of Kafka makes integration with microservices very easy and enables an application to decouple itself with a lot of business logic.
Creating a new Topic
We can create a test Topic testing on Apache Kafka server with the following command:
Creatinig a Topic
sudo kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1--partitions 1 --topic testing
Here is what we get back with this command: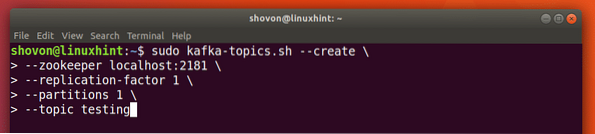
Create New Kafka Topic
A testing topic will be created which we can confirm with the mentioned command:
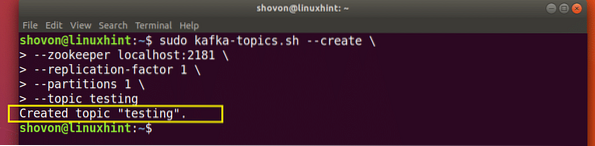
Kafka Topic creation confirmation
Writing Messages on a Topic
As we studied earlier, one of the APIs present in Apache Kafka is the Producer API. We will use this API to create a new message and publish to the topic we just created:
Writing Message to Topic
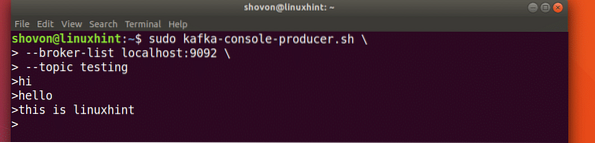
sudo kafka-console-producer.sh --broker-list localhost:9092 --topic testingLet's see the output for this command:
Publish message to Kafka Topic
Once we press key, we will see a new arrow (>) sign which means we can inout data now:

Typing a message
Just type in something and press to start a new line. I typed in 3 lines of texts:
Reading Messages from Topic
Now that we have published a message on the Kafka Topic we created, this message will be there for some configurable time. We can read it now using the Consumer API:
Reading Messages from Topic
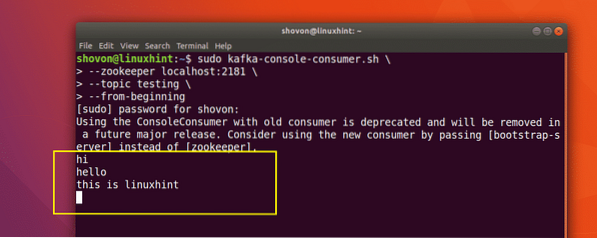
sudo kafka-console-consumer.sh --zookeeper localhost:2181 --topic testing --from-beginning
Here is what we get back with this command:
Command to read Message from Kafka Topic
We will be able to see the messages or lines we have written using the Producer API as shown below:
If we write another new message using the Producer API, it will also be displayed instantly on the Consumer side:
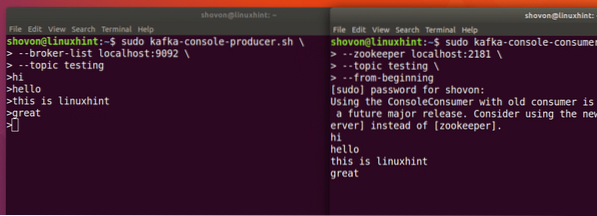
Publish and Consumption at the same time
Conclusion
In this lesson, we looked at how we start using Apache Kafka which is an excellent Message Broker and can act as a special data persistence unit as well.


