Tämä on jatkoartikkeli edelliseen. Käsittelemme kyselyn tarkentamista, monimutkaisempien hakukriteerien muotoilua erilaisilla parametreilla ja ymmärrämme Apache Solr -kyselysivun erilaisia verkkolomakkeita. Keskustelemme myös siitä, miten hakutulos voidaan jälkikäsitellä käyttämällä erilaisia tulostusmuotoja, kuten XML, CSV ja JSON.
Apache Solrin kysely
Apache Solr on suunniteltu verkkosovellukseksi ja palveluksi, joka toimii taustalla. Tuloksena on, että mikä tahansa asiakassovellus voi olla yhteydessä Solriin lähettämällä kyselyjä sille (tämän artikkelin painopiste), manipuloimalla asiakirjan ydintä lisäämällä, päivittämällä ja poistamalla indeksoituja tietoja ja optimoimalla ydintiedot. On olemassa kaksi vaihtoehtoa - kojelaudan / verkkokäyttöliittymän kautta tai API: n avulla lähettämällä vastaava pyyntö.
On yleistä käyttää ensimmäinen vaihtoehto testausta varten eikä säännöllistä käyttöä varten. Alla olevassa kuvassa näkyy Apache Solr Administration -käyttöliittymän hallintapaneeli Firefox-selaimen eri kyselylomakkeilla.
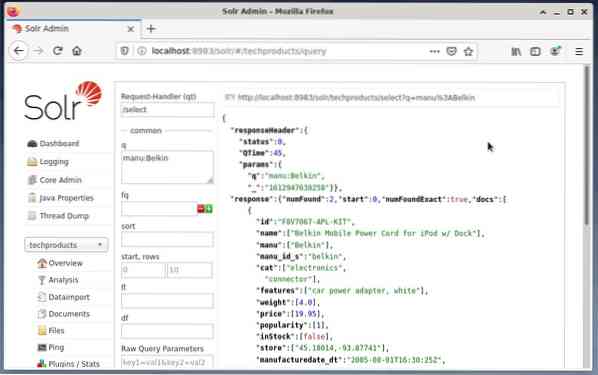
Valitse ensin ydinvalintakentän alla olevasta valikosta valikkokohta "Kysely". Seuraavaksi hallintapaneeli näyttää useita syöttökenttiä seuraavasti:
- Pyynnön käsittelijä (qt):
Määritä minkälainen pyyntö haluat lähettää Solrille. Voit valita oletuskyselyjen käsittelijöiden välillä "/ select" (kyselyn indeksoidut tiedot), "/ update" (päivitä indeksoidut tiedot) ja "/ delete" (poista määritetyt indeksoidut tiedot) tai itse määritetyn välillä. - Kyselytapahtuma (q):
Määritä valitut kenttien nimet ja arvot. - Suodata kyselyt (kysely):
Rajoita palautettavien asiakirjojen pääjoukkoa vaikuttamatta asiakirjan pisteisiin. - Lajittelujärjestys (lajittelu):
Määritä kyselytulosten lajittelujärjestys nousevaksi tai laskevaksi - Lähtöikkuna (alku ja rivit):
Rajoita lähtö määritettyihin elementteihin - Kenttäluettelo (fl):
Rajoittaa kyselyvastaukseen sisältyvät tiedot määritettyyn kenttäluetteloon. - Tulostuksen muoto (paino):
Määritä haluttu tulostusmuoto. Oletusarvo on JSON.
Napsauttamalla Suorita kysely -painiketta suoritetaan haluttu pyyntö. Katso käytännön esimerkkejä alla.
Kuten toinen vaihtoehto, voit lähettää pyynnön sovellusliittymän avulla. Tämä on HTTP-pyyntö, joka voidaan lähettää Apache Solrille millä tahansa sovelluksella. Solr käsittelee pyynnön ja palauttaa vastauksen. Tämän erityistapaus on yhteyden muodostaminen Apache Solriin Java-sovellusliittymän kautta. Tämä on ulkoistettu erilliselle projektille nimeltä SolrJ [7] - Java-sovellusliittymä ilman HTTP-yhteyttä.
Kyselyn syntaksia
Kyselyn syntaksia kuvataan parhaiten kohdissa [3] ja [5]. Eri parametrien nimet vastaavat suoraan edellä selitettyjen lomakkeiden syöttökenttien nimiä. Alla olevassa taulukossa on lueteltu ne sekä käytännön esimerkkejä.
Kyselyparametrien hakemisto
| Parametri | Kuvaus | Esimerkki |
|---|---|---|
| q | Apache Solrin pääkyselyparametri - kenttien nimet ja arvot. Niiden samankaltaisuuspisteet dokumentoivat tämän parametrin termejä. | Id: 5 autot: * adilla * *: X5 |
| fq | Rajoita tulosjoukko superset-asiakirjoihin, jotka vastaavat suodatinta, esimerkiksi määritettynä Function Range Query Parser -toiminnon avulla | malli- id, malli |
| alkaa | Sivutulosten siirtymät (alku). Tämän parametrin oletusarvo on 0. | 5 |
| riviä | Sivutulosten (loppu) siirtymät. Tämän parametrin arvo on oletusarvoisesti 10 | 15 |
| järjestellä | Se määrittää pilkuilla erotettujen kenttien luettelon, jonka perusteella kyselytulokset on lajiteltava | malli asc |
| fl | Se määrittää luettelon palautettavista kentistä kaikista tulosjoukon asiakirjoista | malli- id, malli |
| wt | Tämä parametri edustaa vastauksen kirjoittajan tyyppiä, jonka halusimme tarkastella tulosta. Tämän arvo on oletusarvoisesti JSON. | json xml |
Haut tehdään HTTP GET -pyynnön kautta q-parametrin kyselymerkkijonolla. Alla olevat esimerkit selventävät tämän toimintaa. Käytössä on curl lähettää kysely paikallisesti asennetulle Solrille.
- Hae kaikki tietojoukot ydinautojen käpristyksestä http: // localhost: 8983 / solr / cars / query?q = *: *
- Nouda kaikki tietojoukot ydinautoista, joiden tunnus on 5 curl http: // localhost: 8983 / solr / cars / query?q = id: 5
- Hae kenttämalli kaikista ydinautojen tietojoukoista
Vaihtoehto 1 (pakenemalla &): käpristää http: // localhost: 8983 / solr / cars / query?q = id: * \ & fl = malliVaihtoehto 2 (kysely yksittäisillä punkkeilla):
käpristää 'http: // localhost: 8983 / solr / cars / query?q = id: * & fl = malli ' - Hae kaikki ydinautojen tietojoukot hinnan mukaan lajiteltuina laskevassa järjestyksessä ja anna vain merkit, malli ja hinta (versio yksittäisinä punkkeina): curl http: // localhost: 8983 / solr / cars / query -d '
q = *: * &
lajittelu = hinta desc &
fl = merkki, malli, hinta ' - Hae ydinautojen viisi ensimmäistä tietoaineistoa hinnan mukaan lajiteltuina laskevassa järjestyksessä ja anna vain merkit, malli ja hinta (versio yksittäisinä punkkeina): curl http: // localhost: 8983 / solr / cars / query - d '
q = *: * &
rivit = 5 &
lajittelu = hinta desc &
fl = merkki, malli, hinta ' - Hae ydinautojen viisi ensimmäistä tietoaineistoa hinnan mukaan laskevassa järjestyksessä ja anna vain merkit, malli ja hinta sekä sen relevanssipisteet (versio yksittäisinä punkkeina): kihara http: // localhost: 8983 / solr / autot / kysely -d '
q = *: * &
rivit = 5 &
lajittelu = hinta desc &
fl = merkki, malli, hinta, pisteet ' - Palauta kaikki tallennetut kentät sekä osuvuuspisteet: kihara http: // localhost: 8983 / solr / autot / kysely -d '
q = *: * &
fl = *, pisteet '
Lisäksi voit määrittää oman pyynnön käsittelijän lähettämään valinnaiset kyselyparametrit kyselyn jäsentäjälle palautettavien tietojen hallitsemiseksi.
Kyselyjäsenet
Apache Solr käyttää niin sanottua kyselyn jäsentäjää - komponenttia, joka muuntaa hakumerkkijonosi hakukoneen erityisiksi ohjeiksi. Kyselyn jäsennin seisoo sinun ja etsimäsi asiakirjan välillä.
Solrissa on useita jäsennintyyppejä, jotka eroavat toisistaan lähetetyn kyselyn käsittelytavoissa. Standardi kyselyn jäsennin toimii hyvin strukturoiduissa kyselyissä, mutta on vähemmän suvaitsevainen syntaksivirheiden suhteen. Samaan aikaan sekä DisMax että Extended DisMax Query Parser on optimoitu luonnollisen kielen kaltaisille kyselyille. Ne on suunniteltu käsittelemään käyttäjien kirjoittamia yksinkertaisia lauseita ja etsimään yksittäisiä termejä useilta kentiltä eri painotuksella.
Lisäksi Solr tarjoaa myös ns. Toimintokyselyjä, jotka mahdollistavat funktion yhdistämisen kyselyyn tietyn relevanssipisteen luomiseksi. Nämä jäsennimet on nimetty toimintokyselyjen jäsentäjiksi ja toimintojen kyselyjen jäsentäjiksi. Alla oleva esimerkki osoittaa, että jälkimmäinen valitsee kaikki "bmw" -tietojoukot (tallennetut tietokenttään make) malleilla 318 - 323:
käpristyminen http: // localhost: 8983 / solr / cars / query -d 'q = merkki: bmw &
fq = malli: [318 - 323] '
Tulosten jälkikäsittely
Kyselyjen lähettäminen Apache Solrille on yksi osa, mutta hakutulosten jälkikäsittely toisesta. Ensinnäkin voit valita eri vastausmuotojen välillä - JSON: sta XML: ään, CSV: hen ja yksinkertaistettuun Ruby-muotoon. Määritä vain vastaava wt-parametri kyselyssä. Alla oleva koodiesimerkki osoittaa tämän, kun haetaan tietojoukko CSV-muodossa kaikille kohteille, jotka käyttävät käpristystä pakotetun & kanssa:
käpristää http: // localhost: 8983 / solr / cars / query?q = id: 5 \ & wt = csvTulos on pilkuilla erotettu luettelo seuraavasti:

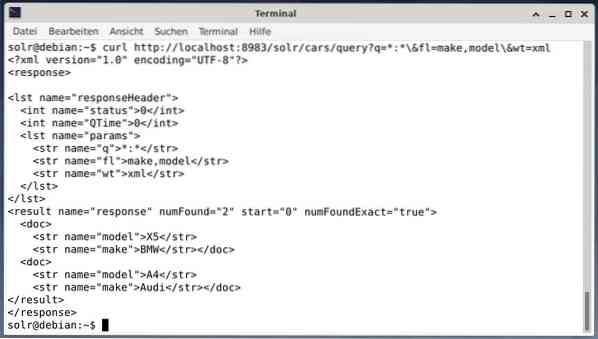
Suorita seuraava kysely saadaksesi tuloksen XML-datana, mutta vain kaksi tuotekenttää, jotka muodostavat ja mallivat:
käpristää http: // localhost: 8983 / solr / cars / query?q = *: * \ & fl = merkki, malli \ & wt = xmlLähtö on erilainen ja sisältää sekä vastausotsikon että todellisen vastauksen:
Wget yksinkertaisesti tulostaa vastaanotetut tiedot vakiona. Tämän avulla voit jälkikäsitellä vastauksen tavallisilla komentorivityökaluilla. Muutama luettelo sisältää tämän: jq [9] JSON: lle, xsltproc, xidel, xmlstarlet [10] XML: lle sekä csvkit [11] CSV-muodolle.
Johtopäätös
Tässä artikkelissa esitetään erilaisia tapoja lähettää kyselyjä Apache Solrille ja selitetään, miten hakutulosta käsitellään. Seuraavassa osassa opit käyttämään Apache Solr -ohjelmaa relaatiotietokannan hallintajärjestelmässä PostgreSQL.
Tietoja kirjoittajista
Jacqui Kabeta on ympäristönsuojelija, innokas tutkija, kouluttaja ja mentori. Hän on työskennellyt useissa Afrikan maissa IT-teollisuudessa ja kansalaisjärjestöjen ympäristössä.
Frank Hofmann on tietotekniikan kehittäjä, kouluttaja ja kirjailija ja mieluummin työskentelee Berliinistä, Genevestä ja Kapkaupungista. Debian Package Management Book -kirjan kirjoittaja, saatavana osoitteesta dpmb.org
Linkit ja viitteet
- [1] Apache Solr, https: // luseeni.apache.org / solr /
- [2] Frank Hofmann ja Jacqui Kabeta: Johdatus Apache Solr -ohjelmaan. Osa 1, http: // linuxhint.com
- [3] Yonik Seelay: Solr Query Syntax, http: // yonik.fi / solr / kyselysyntaksi /
- [4] Yonik Seelay: Solrin opetusohjelma, http: // yonik.fi / solr-tutorial /
- [5] Apache Solr: Tietojen kysely, Tutorialspoint, https: // www.tutorialspoint.fi / apache_solr / apache_solr_querying_data.htm
- [6] Lucene, https: // luseeni.apache.org /
- [7] SolrJ, https: // luseeni.apache.org / solr / guide / 8_8 / using-solrj.html
- [8] käpristyminen, https: // käpristyminen.se /
- [9] jq, https: // github.com / stedolan / jq
- [10] xmlstarlet, http: // xmlstar.sourceforge.netto/
- [11] csvkit, https: // csvkit.readthedocs.io / fi / uusin /


