Introduction
A tree in software is like a biological tree, but with the following differences:
- It is drawn upside-down.
- It has only one root and no stem.
- The branches emerge from the root.
- A point where a branch takes off from another branch or the root is called the node.
- Each node has a value.
The branches of the software tree are represented by straight lines. A good example of a software tree you might have used is the directory tree of the hard disk of your computer.
There are different types of trees. There is the general tree from which other trees are derived. Other trees are derived by introducing constraints into the general tree. For example, you might want a tree where not more than two branches emanate from a node; such a tree would be called a Binary Tree. This article describes the general tree and how to access all its nodes.
The hyperlink to download the code is given at the bottom of this article.
To understand the code samples in this article, you need to have basic knowledge in JavaScript (ECMAScript). If you do not have that knowledge, then you can get it from http://www.broad-network.com/ChrysanthusForcha-1/ECMAScript-2015-Course.htm
The General Tree Diagram
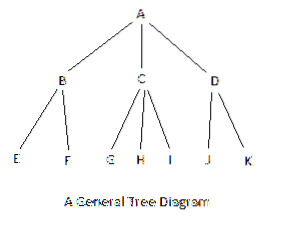
'A' is the root node; it is the first-level node. B, C, D are on the second line; these are second-level nodes. E, F, G, H, I, J, K are on the third line, and they are third-level nodes. A fourth line would have produced fourth level nodes, and so on.
Tree Properties
- All branches for all the levels of nodes, have one source, which is the root node.
- A tree has N - 1 branches, where N is the total number of nodes. The above diagram for the general tree has 11 nodes and 10 branches.
- Unlike with humans, where every child has two parents, with the software tree, every child has only one parent. The root node is the greatest ancestor parent. A parent can have more than one child. Every node, except the root node, is a child.
Tree Vocabulary
- Root Node: This is the highest node in the tree, and it has no parent. Every other node has a parent.
- Leaf Nodes: A leaf node is a node that has no child. They are usually at the bottom of the tree and sometimes are at the left and/or right sides of the tree.
- Key: This is the value of a tree. It can be a number; it can be a string; it can even be an operator such as + or - or x.
- Levels: The root node is at the first level. Its children are at the second level; The children of the second level nodes are at the third level, and so on.
- Parent Node: Every node, except the root node, has a parent node connected to it by a branch. Any node, except the root node, is a child node.
- Sibling Nodes: Sibling nodes are nodes that have the same parent.
- Path: The branches (straight lines) that connect one node to another, through other nodes, form a path. The branches may or may not be arrows.
- Ancestor Node: All the higher nodes connected to a child, including the parent and the root node, are ancestor nodes.
- Descendant Node: All lower nodes connected to a node, right down to connected leaves, are descendant nodes. The node in question, is not part of the descendant nodes. The node in question, does not have to be the root node.
- Subtree: A node plus all its descendants right down to the related leaves, form a subtree. The starting node is included, and it does not have to be the root; otherwise, it would be the whole tree.
- Degree: The number of children a node has is called the degree of the node.
Traversing All Nodes of A Tree
All the nodes of a tree can be accessed to read or change any value of the node. However, this is not done arbitrarily. There are three ways of doing this, all of which involves Depth-First Traversal as follows:
1) In-Order: Simply put, in this scheme, the left subtree is traversed first; then, the root node is accessed; then, the right subtree is traversed. This scheme is symbolized as left->root->right. Fig 1 is re-displayed here for easy reference:
Assuming that there are two siblings per node; then left->root->right means, you access the lowest and leftmost node first, then the parent of the node, and then the right sibling. When there are more than two siblings, take the first as the left and the rest of the right nodes, as the right. For the general tree above, the bottom left subtree is accessed to have, [EBF]. This is a subtree. The parent of this subtree is A; so, A is next accessed to have [EBF]A. Next, the subtree [GCHI] is accessed to have a bigger subtree, [[EBF]A[GCHI]]. You can see the left->root->right profile portraying itself. This big left subtree will have the subtree, [JDK] to its right to complete the traversing to obtain, [[EBF]A[GCHI]] [JDK].
2) Pre-Order: Simply put, in this scheme the root node is accessed first, then the left subtree is traversed next, and then the right subtree is traversed. This scheme is symbolized as root->left->right. Fig 1 is re-displayed here for easy reference.
Assuming that there are two siblings per node; then root->left->right means, you access the root first, then the left immediate child, and then the right immediate child. When there are more than two siblings, take the first as the left and the rest of the right nodes, as the right. The leftmost child of the left child is the next to be accessed. For the general tree above, the root subtree is [ABCD]. To the left of this subtree, you have the subtree, [EF], giving the access sequence, [ABCD][EF]. To the right of this bigger subtree, you have two subtrees, [GHI] and [JK], giving the complete sequence, [ABCD][EF][GHI][JK]. You can see the root->left->right profile portraying itself.
3) Post-Order: Simply put, in this scheme, the left subtree is traversed first, then the right subtree is traversed, and then the root is accessed. This scheme is symbolized as left->right->root. Fig 1 is re-displayed here for easy reference.
For this tree the subtrees are, [EFB], [GHIC], [JKD] and [A] which form the sequence, [EFB], [GHIC], [JKD][A]. You can see the left->right->root profile portraying itself.
Creating the Tree
The above tree will be created using ECMAScript, which is like the latest version of JavaScript. Each node is an array. The first element of each node array is the parent of the node, another array. The rest of the elements of the node are the children of the node, beginning from the leftmost child. There is an ECMAScript map that relates each array to its corresponding string (letter). The first code segment is: