Tässä artikkelissa kerrotaan, kuinka löytää kaksoiskappaleet tiedoista ja poistaa kaksoiskappaleet Pandas Python -toimintojen avulla.
Tässä artikkelissa olemme ottaneet tietojoukon Yhdysvaltojen eri osavaltioiden väestöstä, joka on saatavana a .csv-tiedostomuoto. Luemme .csv-tiedosto näyttääksesi tiedoston alkuperäisen sisällön seuraavasti:
tuoda pandoja pd: nädf_state = pd.read_csv ("C: / Käyttäjät / DELL / Työpöytä / väestö_ds.csv ")
tulosta (df_state)
Seuraavassa kuvakaappauksessa näet tämän tiedoston päällekkäisen sisällön:
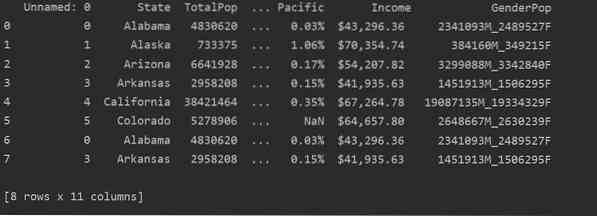
Kopioiden tunnistaminen Pandas Pythonissa
On selvitettävä, onko käyttämilläsi tiedoilla päällekkäisiä rivejä. Voit tarkistaa tietojen päällekkäisyydet käyttämällä mitä tahansa seuraavissa osissa mainittua menetelmää.
Menetelmä 1:
Lue csv-tiedosto ja välitä se datakehykseen. Tunnista sitten kaksoisrivit käyttämällä kopioitu () toiminto. Käytä lopuksi tulostuslauseketta kaksoisrivien näyttämiseen.
tuoda pandoja pd: nädf_state = pd.read_csv ("C: / Käyttäjät / DELL / Työpöytä / väestö_ds.csv ")
Dup_Rows = df_state [df_state.kopioitu ()]
tulosta ("\ n \ nKaksoisrivit: \ n ".muoto (Dup_Rows))
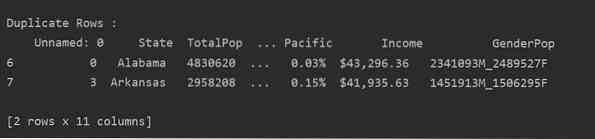
Menetelmä 2:
Tätä menetelmää käyttämällä is_duplicated -sarake lisätään taulukon loppuun ja merkitään 'True', jos kyseessä on päällekkäinen rivi.
tuoda pandoja pd: nädf_state = pd.read_csv ("C: / Käyttäjät / DELL / Työpöytä / väestö_ds.csv ")
df_state ["is_duplicate"] = df_state.kopioitu ()
tulosta ("\ n ".muoto (df_state))
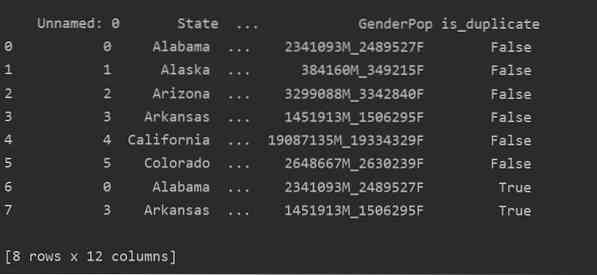
Kopioiden pudottaminen Pandas Pythoniin
Päällekkäiset rivit voidaan poistaa datakehyksestä seuraavan syntaksin avulla:
drop_duplicates (osajoukko = ", keep =", inplace = väärä)
Edellä olevat kolme parametria ovat valinnaisia, ja ne selitetään yksityiskohtaisemmin alla:
pitää: tällä parametrilla on kolme erilaista arvoa: First, Last ja False. Ensimmäinen arvo pitää ensimmäisen esiintymän ja poistaa seuraavat kaksoiskappaleet, Viimeinen arvo pitää vain viimeisen esiintymän ja poistaa kaikki aiemmat kaksoiskappaleet, ja Väärä-arvo poistaa kaikki päällekkäiset rivit.
osajoukko: tunniste, jota käytetään kaksoiskappaleiden tunnistamiseen
paikallaan: sisältää kaksi ehtoa: tosi ja väärä. Tämä parametri poistaa päällekkäiset rivit, jos se on asetettu True.
Poista kaksoiskappaleet säilyttäen vain ensimmäisen esiintymisen
Kun valitset “keep = first”, vain ensimmäinen rivi esiintyy ja kaikki muut kaksoiskappaleet poistetaan.
Esimerkki
Tässä esimerkissä vain ensimmäinen rivi säilytetään ja loput kaksoiskappaleet poistetaan:
tuoda pandoja pd: nädf_state = pd.read_csv ("C: / Käyttäjät / DELL / Työpöytä / väestö_ds.csv ")
Dup_Rows = df_state [df_state.kopioitu ()]
tulosta ("\ n \ nKaksoisrivit: \ n ".muoto (Dup_Rows))
DF_RM_DUP = df_state.drop_duplicates (pidä = 'ensimmäinen')
tulosta ('\ n \ nTulos DataFrame kaksoiskappaleen poiston jälkeen: \ n', DF_RM_DUP.pää (n = 5))
Seuraavassa kuvakaappauksessa säilytetty ensimmäisen rivin esiintymä on korostettu punaisella ja loput kopiot poistetaan:
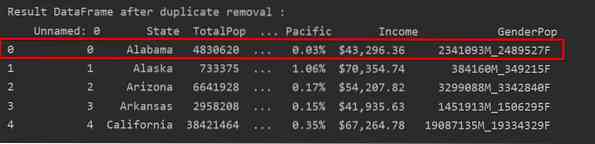
Poista kopiot säilyttämällä vain viimeinen esiintymä
Kun valitset “keep = last”, kaikki kaksoisrivit viimeistä esiintymää lukuun ottamatta poistetaan.
Esimerkki
Seuraavassa esimerkissä kaikki päällekkäiset rivit poistetaan paitsi viimeinen esiintymä.
tuoda pandoja pd: nädf_state = pd.read_csv ("C: / Käyttäjät / DELL / Työpöytä / väestö_ds.csv ")
Dup_Rows = df_state [df_state.kopioitu ()]
tulosta ("\ n \ nKaksoisrivit: \ n ".muoto (Dup_Rows))
DF_RM_DUP = df_state.drop_duplicates (keep = 'viimeinen')
tulosta ('\ n \ nTulos DataFrame kaksoiskappaleen poiston jälkeen: \ n', DF_RM_DUP.pää (n = 5))
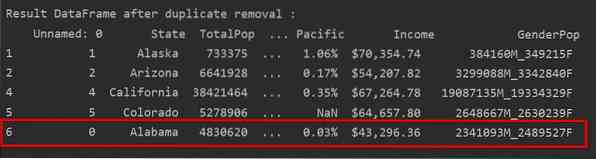
Seuraavassa kuvassa kaksoiskappaleet poistetaan ja vain viimeinen rivi esiintyy:
Poista kaikki kaksoiskappaleet
Jos haluat poistaa kaikki kaksoisrivit taulusta, aseta ”keep = False” seuraavasti:
tuoda pandoja pd: nädf_state = pd.read_csv ("C: / Käyttäjät / DELL / Työpöytä / väestö_ds.csv ")
Dup_Rows = df_state [df_state.kopioitu ()]
tulosta ("\ n \ nKaksoisrivit: \ n ".muoto (Dup_Rows))
DF_RM_DUP = df_state.drop_duplicates (pidä = väärä)
tulosta ('\ n \ nTulos DataFrame kaksoiskappaleen poiston jälkeen: \ n', DF_RM_DUP.pää (n = 5))
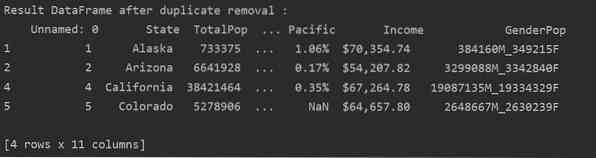
Kuten seuraavasta kuvasta näet, kaikki kaksoiskappaleet poistetaan datakehyksestä:
Poista liittyvät kaksoiskappaleet määritetystä sarakkeesta
Oletusarvoisesti toiminto tarkistaa kaikki kaksoisrivit tietyn kehyksen kaikista sarakkeista. Mutta voit myös määrittää sarakkeen nimen käyttämällä osajoukko-parametria.
Esimerkki
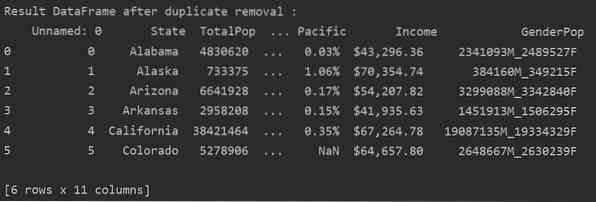
Seuraavassa esimerkissä kaikki siihen liittyvät kaksoiskappaleet poistetaan valtiot-sarakkeesta.
tuoda pandoja pd: nädf_state = pd.read_csv ("C: / Käyttäjät / DELL / Työpöytä / väestö_ds.csv ")
Dup_Rows = df_state [df_state.kopioitu ()]
tulosta ("\ n \ nKaksoisrivit: \ n ".muoto (Dup_Rows))
DF_RM_DUP = df_state.drop_duplicates (osajoukko = 'tila')
tulosta ('\ n \ nTulos DataFrame kaksoiskappaleen poiston jälkeen: \ n', DF_RM_DUP.pää (n = 6))
Johtopäätös
Tässä artikkelissa kerrotaan, kuinka päällekkäiset rivit poistetaan datakehyksestä drop_duplicates () Pandas Pythonissa. Tämän toiminnon avulla voit myös tyhjentää tietosi päällekkäisyydestä tai redundanssista. Artikkeli osoitti myös, kuinka tunnistaa mahdolliset kaksoiskappaleet tietokehyksessäsi.

