Tässä artikkelissa käymme läpi ryhmien perustiedot käyttötarkoitusten mukaan pandan pythonissa. Kaikki komennot suoritetaan Pycharm-editorissa.
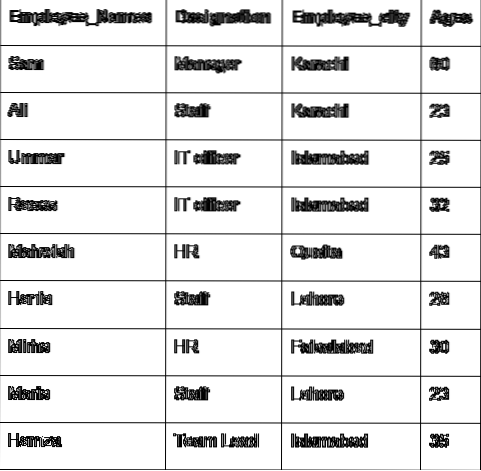
Keskustellaan ryhmän pääkäsitteestä työntekijän tietojen avulla. Olemme luoneet tietokehyksen, jossa on hyödyllisiä työntekijän tietoja (työntekijän nimet, nimitys, työntekijän kaupunki, ikä).
Merkkijonon ketjutus ryhmittäin toiminnon mukaan
Groupby-toiminnolla voit ketjuttaa merkkijonoja. Samat tietueet voidaan liittää ',' -merkillä yhteen soluun.
Esimerkki
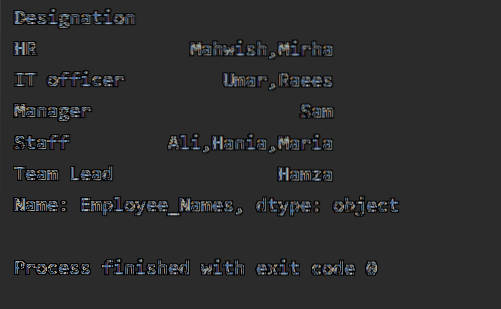
Seuraavassa esimerkissä olemme lajittelleet tiedot työntekijöiden nimeämissarakkeen perusteella ja liittyneet työntekijöihin, joilla on sama nimitys. Lambda-toimintoa sovelletaan kohtaan 'Employees_Name'.
tuoda pandoja pd: nädf = pd.Datakehys(
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
Nimitys: [”Johtaja”, ”Henkilöstö”, ”IT-upseeri”, ”IT-upseeri”, ”HR”, ”Henkilöstö”, “HR”, ”Henkilökunta”, ”Tiimin johtaja”],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Työntekijän ikä': [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df1 = df.groupby ("Nimitys") ['Työntekijänimet'].sovelletaan (lambda Employee_Names: ','.liittyä (Employee_Names))
tulosta (df1)
Kun yllä oleva koodi suoritetaan, seuraava tulos näkyy:
Arvojen lajittelu nousevassa järjestyksessä
Käytä groupby-objektia tavalliseen datakehykseen kutsumalla.to_frame () 'ja käytä sitten uudelleenindeksointia reset_index (). Lajittele sarakearvot kutsumalla lajitteluarvot ().
Esimerkki
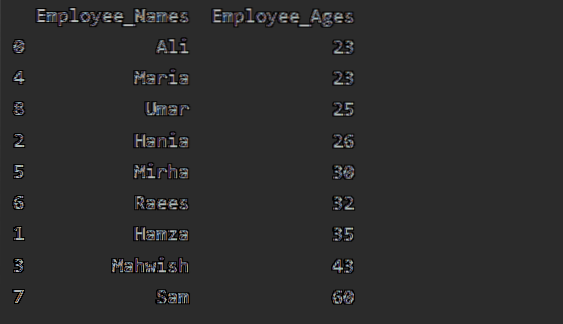
Tässä esimerkissä lajitellaan työntekijän ikä nousevassa järjestyksessä. Seuraavan koodinpätkän avulla olemme hakeneet 'Employee_Age' nousevassa järjestyksessä nimellä 'Employee_Names'.
tuoda pandoja pd: nädf = pd.Datakehys(
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
Nimitys: [”Johtaja”, ”Henkilöstö”, ”IT-upseeri”, ”IT-upseeri”, ”HR”, ”Henkilöstö”, “HR”, ”Henkilökunta”, ”Tiimin johtaja”],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Työntekijän ikä': [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df1 = df.groupby ('Työntekijänimet') ['Työntekijän ikä'].summa().kehystää().reset_index ().lajitteluarvot (by = 'Työntekijän ikä')
tulosta (df1)
Aggregaattien käyttö groupbyn kanssa
Saatavilla on useita toimintoja tai yhdistelmiä, joita voit käyttää tietoryhmissä, kuten määrä (), summa (), keskiarvo (), mediaani (), tila (), vakio (), min (), max ().
Esimerkki
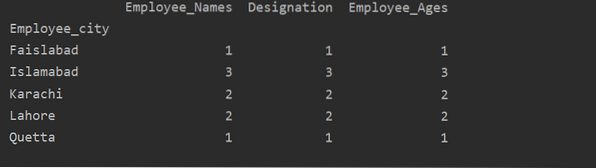
Tässä esimerkissä olemme käyttäneet 'count ()' -funktiota groupby-ryhmällä laskemaan työntekijät, jotka kuuluvat samaan 'Employee_city'.
tuoda pandoja pd: nädf = pd.Datakehys(
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
Nimitys: [”Johtaja”, ”Henkilöstö”, ”IT-upseeri”, ”IT-upseeri”, ”HR”, ”Henkilöstö”, ”HR”, ”Henkilökunta”, ”Tiimin johtaja”],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Työntekijän ikä': [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df1 = df.groupby ('Työntekijän_kaupunki').Kreivi()
tulosta (df1)
Kuten näet seuraavan tuotoksen, laskekaa sarakkeet Nimitys, Työntekijän nimet ja Työntekijän_Age sarakkeet, jotka kuuluvat samaan kaupunkiin:
Visualisoi tiedot ryhmäkomennolla
Käyttämällä 'tuo matplotlib.pyplot ', voit visualisoida tietosi kaavioiksi.
Esimerkki
Tässä seuraava esimerkki visualisoi 'Employee_Age' ja 'Employee_Nmaes' annetusta DataFrame-kehyksestä käyttämällä groupby-lausetta.
tuoda pandoja pd: nätuoda matplotlib.pyplot kuten plt
datakehys = pd.Datakehys(
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
Nimitys: [”Johtaja”, ”Henkilöstö”, ”IT-upseeri”, ”IT-upseeri”, ”HR”, ”Henkilöstö”, “HR”, ”Henkilökunta”, ”Tiimin johtaja”],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Työntekijän ikä': [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
plt.clf ()
datakehys.groupby ('Työntekijänimet').summa().juoni (kind = 'bar')
plt.näytä()
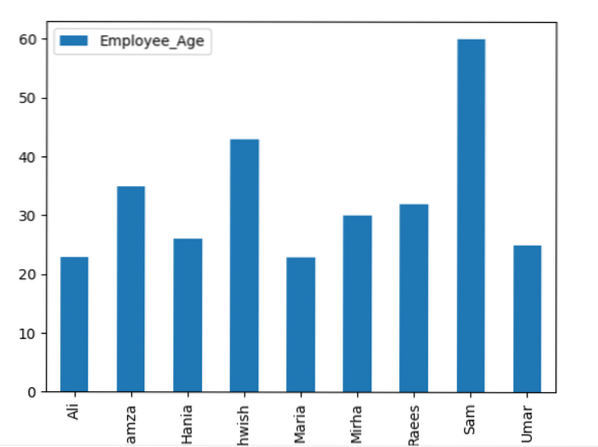
Esimerkki
Jos haluat piirtää pinotun kaavion ryhmäkomennolla, käännä 'pinottu = tosi' ja käytä seuraavaa koodia:
tuoda pandoja pd: nätuoda matplotlib.pyplot kuten plt
df = pd.Datakehys(
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
Nimitys: [”Johtaja”, ”Henkilöstö”, ”IT-upseeri”, ”IT-upseeri”, ”HR”, ”Henkilöstö”, ”HR”, ”Henkilökunta”, ”Tiimin johtaja”],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Työntekijän ikä': [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df.groupby (['Työntekijän_kaupunki', 'Työntekijän_nimet']).koko().pura ().juoni (kind = 'bar', pinottu = True, fontsize = '6')
plt.näytä()
Alla olevassa kaaviossa pinottujen työntekijöiden määrä, jotka kuuluvat samaan kaupunkiin.
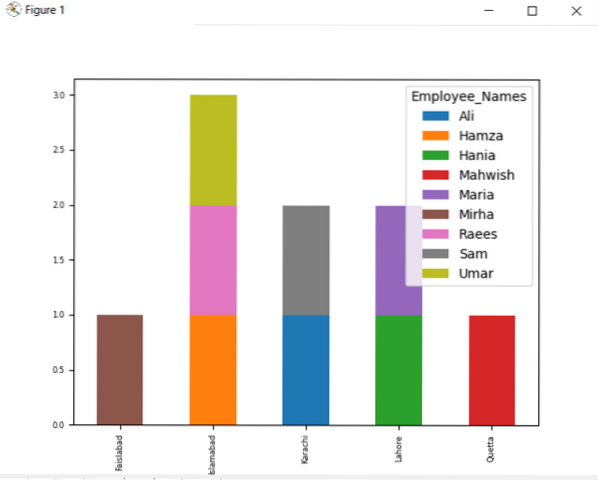
Vaihda sarakkeen nimi ryhmällä
Voit myös muuttaa kootun sarakkeen nimen uudella muokatulla nimellä seuraavasti:
tuoda pandoja pd: nätuoda matplotlib.pyplot kuten plt
df = pd.Datakehys(
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
Nimitys: [”Johtaja”, ”Henkilöstö”, ”IT-upseeri”, ”IT-upseeri”, ”HR”, ”Henkilöstö”, ”HR”, ”Henkilökunta”, ”Tiimin johtaja”],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Työntekijän ikä': [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df1 = df.groupby ('Employee_Names') ['Nimitys'].summa().reset_index (nimi = 'Employee_Designation')
tulosta (df1)
Yllä olevassa esimerkissä nimityksen nimi muutetaan nimeksi Employee_Designation.
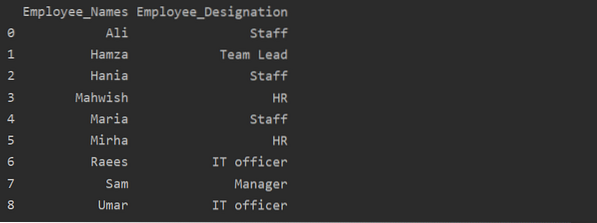
Hae ryhmä avaimella tai arvolla
Groupby-käskyä käyttämällä voit hakea samanlaisia tietueita tai arvoja datakehyksestä.
Esimerkki
Alla olevassa esimerkissä meillä on ryhmätiedot nimityksen perusteella. Sitten 'Henkilöstö' -ryhmä haetaan käyttämällä .getgroup ('Henkilökunta').
tuoda pandoja pd: nätuoda matplotlib.pyplot kuten plt
df = pd.Datakehys(
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
Nimitys: [”Johtaja”, ”Henkilöstö”, ”IT-upseeri”, ”IT-upseeri”, ”HR”, ”Henkilöstö”, “HR”, ”Henkilökunta”, ”Tiimin johtaja”],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Työntekijän ikä': [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
poimi_arvo = df.groupby ('nimitys')
tulosta (pura_arvo.get_group ('Henkilökunta'))
Seuraava tulos näkyy lähtöikkunassa:

Lisää arvoa ryhmäluetteloon
Samankaltaiset tiedot voidaan näyttää luettelona käyttämällä groupby-käskyä. Ryhmittele ensin tiedot ehdon perusteella. Sitten soveltamalla funktiota voit helposti lisätä tämän ryhmän luetteloihin.
Esimerkki
Tässä esimerkissä olemme lisänneet samanlaisia tietueita ryhmäluetteloon. Kaikki työntekijät on jaettu ryhmään Työntekijän_kaupungin perusteella, ja sitten Lambda-funktiota käyttämällä tämä ryhmä haetaan luettelon muodossa.
tuoda pandoja pd: nädf = pd.Datakehys(
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
Nimitys: [”Johtaja”, ”Henkilöstö”, ”IT-upseeri”, ”IT-upseeri”, ”HR”, ”Henkilöstö”, “HR”, ”Henkilökunta”, ”Tiimin johtaja”],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Työntekijän ikä': [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df1 = df.groupby ('Työntekijän_kaupunki') ['Työntekijän_nimi'].soveltaa (lambda ryhmä_sarja: ryhmä_sarja.listata()).reset_index ()
tulosta (df1)
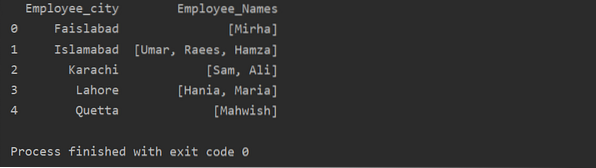
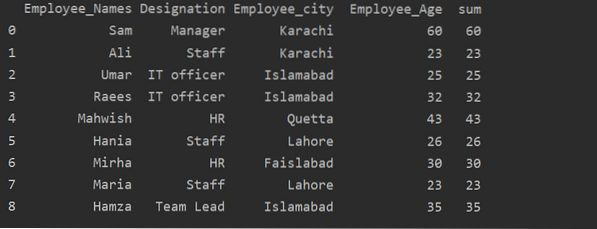
Muunna-toiminnon käyttö ryhmäkomennolla
Työntekijät on ryhmitelty heidän ikänsä mukaan, nämä arvot lasketaan yhteen, ja 'muunnos' -toiminnon avulla uusi sarake lisätään taulukkoon:
tuoda pandoja pd: nädf = pd.Datakehys(
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
Nimitys: [”Johtaja”, ”Henkilöstö”, ”IT-upseeri”, ”IT-upseeri”, ”HR”, ”Henkilöstö”, “HR”, ”Henkilökunta”, ”Tiimin johtaja”],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Työntekijän ikä': [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df ['summa'] = df.groupby (['Employee_Names']) ['Employee_Age'].muunnos ('summa')
tulosta (df)
Johtopäätös
Tässä artikkelissa olemme tutkineet ryhmälausekkeen eri käyttötarkoituksia. Olemme osoittaneet, miten voit jakaa tiedot ryhmiin, ja soveltamalla erilaisia aggregaatteja tai toimintoja voit helposti hakea nämä ryhmät.


