Tämä on jatkoartikkeli kahdelle edelliselle [2,3]. Toistaiseksi ladasimme indeksoidut tiedot Apache Solr -muistiin ja kysyimme niistä tietoja. Nyt opit yhdistämään relaatiotietokantojen hallintajärjestelmän PostgreSQL [4] Apache Solr -ohjelmaan ja tekemään siinä haun Solrin ominaisuuksien avulla. Tämän vuoksi on tarpeen tehdä useita alla kuvattuja vaiheita yksityiskohtaisemmin - asettaa PostgreSQL, valmistella tietorakenne PostgreSQL-tietokantaan ja yhdistää PostgreSQL Apache Solriin ja tehdä hakumme.
Vaihe 1: PostgreSQL: n määrittäminen
Tietoja PostgreSQL: stä - lyhyt info
PostgreSQL on nerokas objekti-relaatiotietokantojen hallintajärjestelmä. Se on ollut käytettävissä ja sitä on kehitetty aktiivisesti yli 30 vuoden ajan. Se on peräisin Kalifornian yliopistosta, jossa sitä pidetään Ingresin seuraajana [7].
Alusta alkaen se on saatavana avoimen lähdekoodin (GPL) alaisuudessa, vapaasti käytettävissä, muokattavissa ja jakelussa. Se on laajalti käytetty ja erittäin suosittu teollisuudessa. PostgreSQL on alun perin suunniteltu toimimaan vain UNIX / Linux-järjestelmissä, ja myöhemmin se on suunniteltu toimimaan muissa järjestelmissä, kuten Microsoft Windows, Solaris ja BSD. PostgreSQL: n nykyistä kehitystä tekevät lukuisat vapaaehtoiset maailmanlaajuisesti.
PostgreSQL-asetukset
Jos sitä ei ole vielä tehty, asenna PostgreSQL-palvelin ja asiakas paikallisesti, esimerkiksi Debian GNU / Linuxiin alla kuvatulla tavalla apt: n avulla. Kaksi artikkelia käsittelee PostgreSQL: ää - Yunis Saidin artikkelissa [5] käsitellään Ubuntun asetuksia. Silti hän vain naarmuttaa pintaa, kun edellisessä artikkelissani keskityn PostgreSQL: n ja PostGIS: n GIS-laajennuksen yhdistelmään [6]. Tässä oleva kuvaus sisältää yhteenvedon kaikista tarvittavista vaiheista tässä asetuksessa.
# apt install postgresql-13 postgresql-client-13Tarkista seuraavaksi, että PostgreSQL on käynnissä komennon pg_isready avulla. Tämä on apuohjelma, joka on osa PostgreSQL-pakettia.
# pg_isready/ var / run / postgresql: 5432 - Yhteydet hyväksytään
Yllä oleva lähtö osoittaa, että PostgreSQL on valmis ja odottaa saapuvia yhteyksiä porttiin 5432. Ellei toisin ole asetettu, tämä on vakiokonfiguraatio. Seuraava vaihe on UNIX-käyttäjän Postgres-salasanan asettaminen:
# passwd PostgresMuista, että PostgreSQL: llä on oma käyttäjätietokanta, kun taas hallinnollisella PostgreSQL-käyttäjällä Postgresillä ei ole vielä salasanaa. Edellinen vaihe on tehtävä myös PostgreSQL-käyttäjälle Postgres:
# su - Postgres$ psql -c "ALTER USER Postgres WITH PASSWORD 'password';"
Yksinkertaisuuden vuoksi valittu salasana on vain salasana, ja se tulisi korvata turvallisemmalla salasanailmauksella muissa järjestelmissä kuin testauksessa. Yllä oleva komento muuttaa PostgreSQL: n sisäistä käyttäjätaulukkoa. Ole tietoinen erilaisista lainausmerkeistä - salasana yksittäisissä lainausmerkeissä ja SQL-kysely kaksoislainausmerkeissä, jotta shell-tulkki ei voi arvioida komentoa väärin. Lisää myös puolipiste SQL-kyselyn jälkeen ennen kaksoislainauksia komennon lopussa.
Seuraavaksi, hallinnollisista syistä, muodosta yhteys PostgreSQL: ään käyttäjän Postgres-tiedostona aiemmin luodulla salasanalla. Komennoa kutsutaan psql:
$ psqlYhdistäminen Apache Solrista PostgreSQL-tietokantaan tapahtuu käyttäjän solrina. Joten lisätään PostgreSQL-käyttäjän solr ja määritetään vastaava salasanan solr hänelle yhdellä kertaa:
$ CREATE USER solr WITH PASSWD 'solr';Yksinkertaisuuden vuoksi valittu salasana on vain solr ja se tulisi korvata turvallisemmalla salasanalauseella tuotannossa olevissa järjestelmissä.
Vaihe 2: Tietorakenteen valmistelu
Tietojen tallentamiseen ja hakemiseen tarvitaan vastaava tietokanta. Alla oleva komento luo tietokannan autoista, jotka kuuluvat käyttäjän solr-tilaan ja joita käytetään myöhemmin.
$ LUO TIETOKANTA-auto, jolla on omistaja = solr;Yhdistä sitten vasta luotuihin tietokanta-autoihin käyttäjän solrina. Vaihtoehto -d (lyhyt vaihtoehto -dbname) määrittelee tietokannan nimen ja -U (lyhyt vaihtoehto -username) PostgreSQL-käyttäjän nimen.
$ psql -d autot -U solrTyhjä tietokanta ei ole hyödyllinen, mutta sisältöä sisältävät strukturoidut taulukot. Luo pöytäautojen rakenne seuraavasti:
$ CREATE TABLE -autot (id int,
tehdä varchar (100),
mallivarchar (100),
kuvaus varchar (100),
värivarchar (50),
hinta sis
);
Pöytäautoissa on kuusi tietokenttää - id (kokonaisluku), merkki (pituus 100 merkkijono), malli (pituus 100 merkkijono), kuvaus (pituus 100 merkkijono), väri (pituus 50 merkkijono) ja hinta (kokonaisluku). Jos haluat saada joitain näytetietoja, lisää seuraavat arvot taulukkoautoihin SQL-käskyinä:
$ INSERT INTO autot (tunnus, merkki, malli, kuvaus, väri, hinta)ARVOT (1, 'BMW', 'X5', 'Viileä auto', 'harmaa', 45000);
$ INSERT INTO autot (tunnus, merkki, malli, kuvaus, väri, hinta)
ARVOT (2, 'Audi', 'Quattro', 'kilpa-auto', 'valkoinen', 30000);
Tuloksena on kaksi merkintää, jotka edustavat harmaata BMW X5 -autoa, joka maksaa 45000 USD, jota kutsutaan viileäksi autoksi, ja valkoista kilpa-autoa Audi Quattro, joka maksaa 30000 USD.
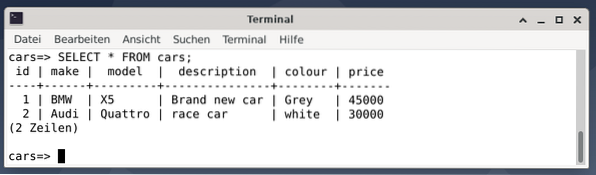
Poistu seuraavaksi PostgreSQL-konsolista painamalla \ q tai lopeta.
$ \ qVaihe 3: PostgreSQL: n yhdistäminen Apache Solriin
PostgreSQL- ja Apache Solr -yhteydet perustuvat kahteen ohjelmistoon - Java-ajuri PostgreSQL: lle nimeltä Java Database Connectivity (JDBC) -ohjain ja laajennus Solr-palvelimen kokoonpanoon. JDBC-ohjain lisää Java-käyttöliittymän PostgreSQL: ään, ja Solr-kokoonpanon lisämerkintä kertoo Solrille yhteyden muodostamisen PostgreSQL: ään JDBC-ohjaimen avulla.
JDBC-ohjaimen lisääminen tapahtuu käyttäjän juurina seuraavasti ja asentaa JDBC-ohjaimen Debian-pakettivarastosta:
# apt-get install libpostgresql-jdbc-javaApache Solr -puolella on myös oltava vastaava solmu. Jos sitä ei ole vielä tehty, luo solmuautot UNIX-käyttäjän Solr-sovelluksena seuraavasti:
$ bin / solr luo -c autojaLaajenna seuraavaksi uuden luodun solmun Solr-kokoonpanoa. Lisää alla olevat rivit tiedostoon / var / solr / data / cars / conf / solrconfig.xml:
db-data-config.xmlLuo lisäksi tiedosto / var / solr / data / cars / conf / data-config.xml ja tallenna siihen seuraava sisältö:
Yllä olevat rivit vastaavat edellisiä asetuksia ja määrittelevät JDBC-ohjaimen, määritä portti 5432 yhteyden muodostamiseksi PostgreSQL DBMS: ään käyttäjän solrina vastaavalla salasanalla ja aseta SQL-kysely suoritettavaksi PostgreSQL: stä. Yksinkertaisuuden vuoksi se on SELECT-käsky, joka tarttuu taulukon koko sisältöön.
Käynnistä sitten Solr-palvelin uudelleen aktivoidaksesi muutokset. Käyttäjäjuurena suorittaa seuraava komento:
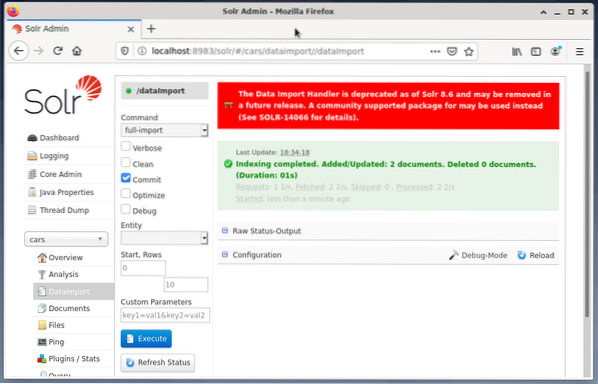
# systemctl uudelleenkäynnistys solrViimeinen vaihe on tietojen tuonti esimerkiksi Solr-web-käyttöliittymän avulla. Solmun valintaruutu valitsee solmuautot, sitten solmuvalikosta kohdan Dataimport alapuolella ja sen jälkeen täydellisen tuonnin valitsemisen Komento-valikosta suoraan siihen. Paina lopuksi Suorita-painiketta. Alla oleva kuva osoittaa, että Solr on indeksoinut tiedot onnistuneesti.
Vaihe 4: Tietojen kysely DBMS: stä
Edellinen artikkeli [3] käsittelee tietojen kyselyä yksityiskohtaisesti, tuloksen noutamista ja halutun tulostusmuodon valitsemista - CSV, XML tai JSON. Tietojen kysely tapahtuu samalla tavalla kuin olet oppinut aiemmin, eikä käyttäjälle näy mitään eroa. Solr tekee kaiken työn kulissien takana ja kommunikoi PostgreSQL DBMS: n kanssa, joka on kytketty valitun Solr-ytimen tai klusterin mukaisesti.
Solrin käyttö ei muutu, ja kyselyt voidaan lähettää Solrin järjestelmänvalvojan käyttöliittymän kautta tai käyttämällä komentorivillä curl tai wget. Lähetät tietyn URL-osoitteen sisältävän Get-pyynnön Solr-palvelimelle (kysely, päivitys tai poisto). Solr käsittelee pyynnön käyttämällä DBMS: ää tallennusyksikkönä ja palauttaa pyynnön tuloksen. Käsittele seuraavaksi vastaus paikallisesti.
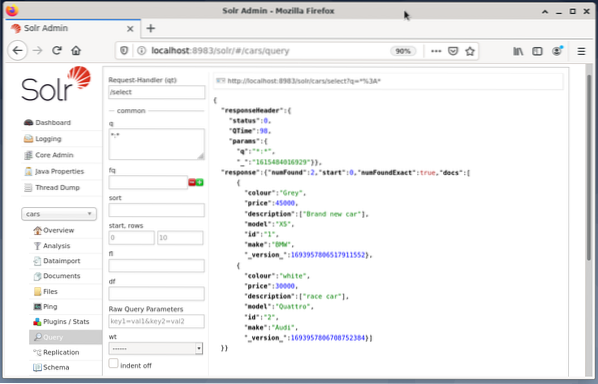
Alla olevassa esimerkissä näkyy kyselyn "/ select" tulos?q = *. * ”JSON-muodossa Solrin järjestelmänvalvojan käyttöliittymässä. Tiedot haetaan aiemmin luomistamme tietokanta-autoista.
Johtopäätös
Tässä artikkelissa kerrotaan, miten PostgreSQL-tietokannasta tehdään kysely Apache Solrilta, ja selitetään vastaava asennus. Tämän sarjan seuraavassa osassa opit yhdistämään useita Solr-solmuja Solr-klusteriksi.
Tietoja kirjoittajista
Jacqui Kabeta on ympäristönsuojelija, innokas tutkija, kouluttaja ja mentori. Hän on työskennellyt useissa Afrikan maissa IT-teollisuudessa ja kansalaisjärjestöjen ympäristössä.
Frank Hofmann on tietotekniikan kehittäjä, kouluttaja ja kirjailija ja mieluummin työskentelee Berliinistä, Genevestä ja Kapkaupungista. Debian Package Management Book -kirjan kirjoittaja, saatavana osoitteesta dpmb.org
Linkit ja viitteet
- [1] Apache Solr, https: // luseeni.apache.org / solr /
- [2] Frank Hofmann ja Jacqui Kabeta: Johdatus Apache Solr -ohjelmaan. Osa 1, https: // linuxhint.fi / apache-solr-setup-a-solmu /
- [3] Frank Hofmann ja Jacqui Kabeta: Johdatus Apache Solr -ohjelmaan. Tietojen kysely. Osa 2, http: // linuxhint.com
- [4] PostgreSQL, https: // www.postgresql.org /
- [5] Younis sanoi: PostgreSQL-tietokannan asentaminen ja asentaminen Ubuntu 20: een.04, https: // linuxhint.fi / install_postgresql_-ubuntu /
- [6] Frank Hofmann: PostgreSQL: n määrittäminen PostGIS: n avulla Debian GNU / Linux 10: ssä, https: // linuxhint.fi / setup_postgis_debian_postgres /
- [7] Ingres, Wikipedia, https: // en.wikipedia.org / wiki / Ingres_ (tietokanta)


